快速入门
通过构建一个由 OpenAI 驱动的聊天机器人应用来了解 Langflow。构建好聊天机器人后,添加检索增强生成 (RAG) 功能,以便使用您自己的数据进行聊天。
先决条件
- 一个正在运行的 Langflow 实例
- 一个 OpenAI API 密钥
- 一个 Astra DB 向量数据库 以及
- 一个具有读写数据库权限范围的 Astra DB 应用令牌
- 在 Astra 中创建的一个集合,或在 Astra DB 组件中创建的一个新集合
打开 Langflow 并开始一个新项目
- 从 Langflow 面板中,点击 New Flow(新建流程),然后选择 Blank Flow(空白流程)。一个空白工作区将打开,您可以在其中构建您的流程。
如果您想要一个预构建的流程,点击 New Flow(新建流程),然后选择 Basic Prompting(基本提示)。继续前往运行基本提示流程。
-
选择 Basic Prompting(基本提示)。
-
Basic Prompting(基本提示)流程已创建。
构建基本提示流程
基本提示流程完成后将如下图所示
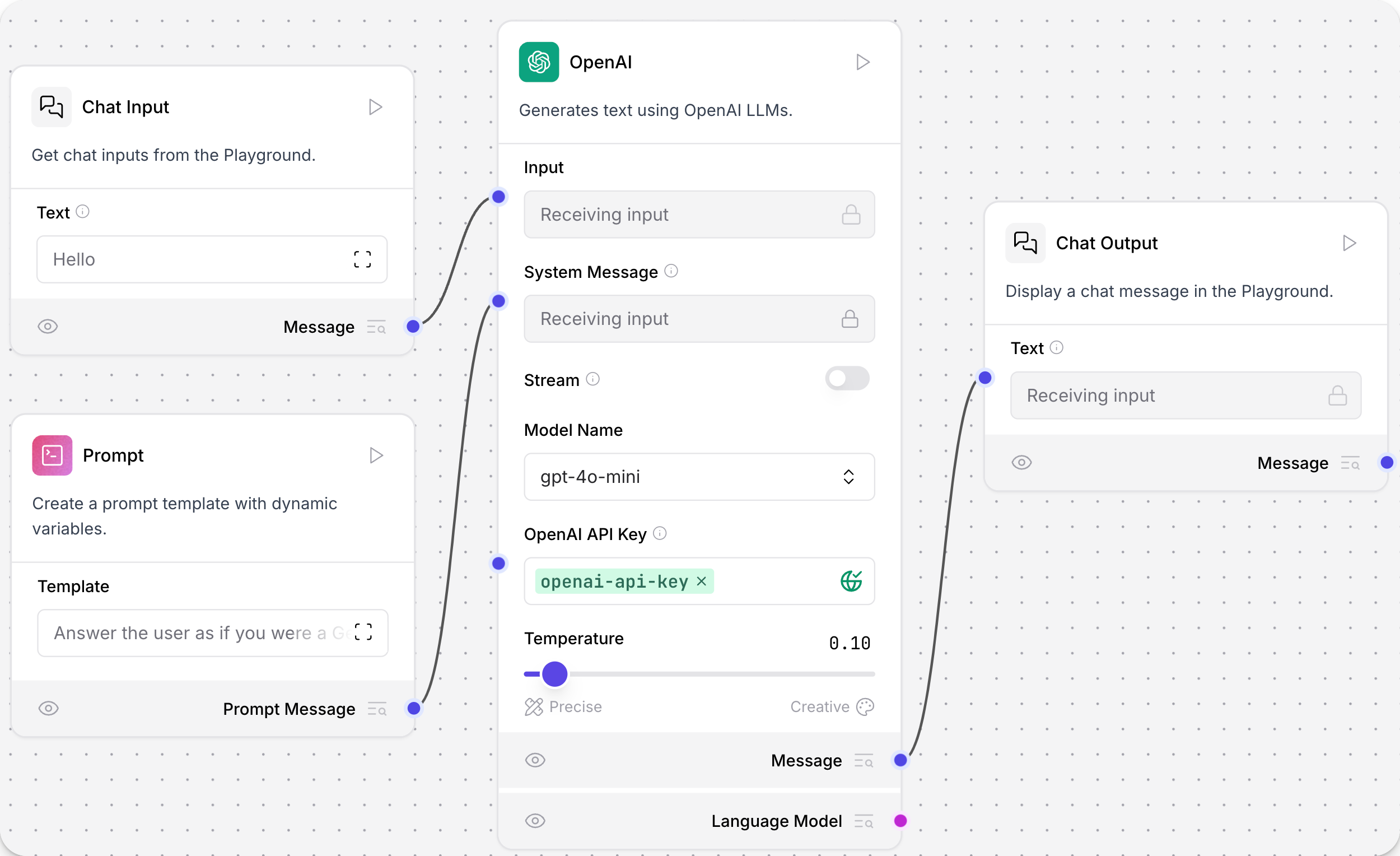
要构建 Basic Prompting(基本提示)流程,请按照以下步骤操作
- 点击 Inputs(输入),选择 Chat Input(聊天输入)组件,然后将其拖动到画布上。Chat Input(聊天输入)组件接受用户输入到聊天中。
- 点击 Prompt(提示),选择 Prompt(提示)组件,然后将其拖动到画布上。Prompt(提示)组件将用户输入与用户定义的提示结合起来。
- 点击 Outputs(输出),选择 Chat Output(聊天输出)组件,然后将其拖动到画布上。Chat Output(聊天输出)组件将流程的输出打印到聊天中。
- 点击 Models(模型),选择 OpenAI 组件,然后将其拖动到画布上。OpenAI 模型组件将用户输入和提示发送到 OpenAI API 并接收响应。
您现在应该有一个如下图所示的流程
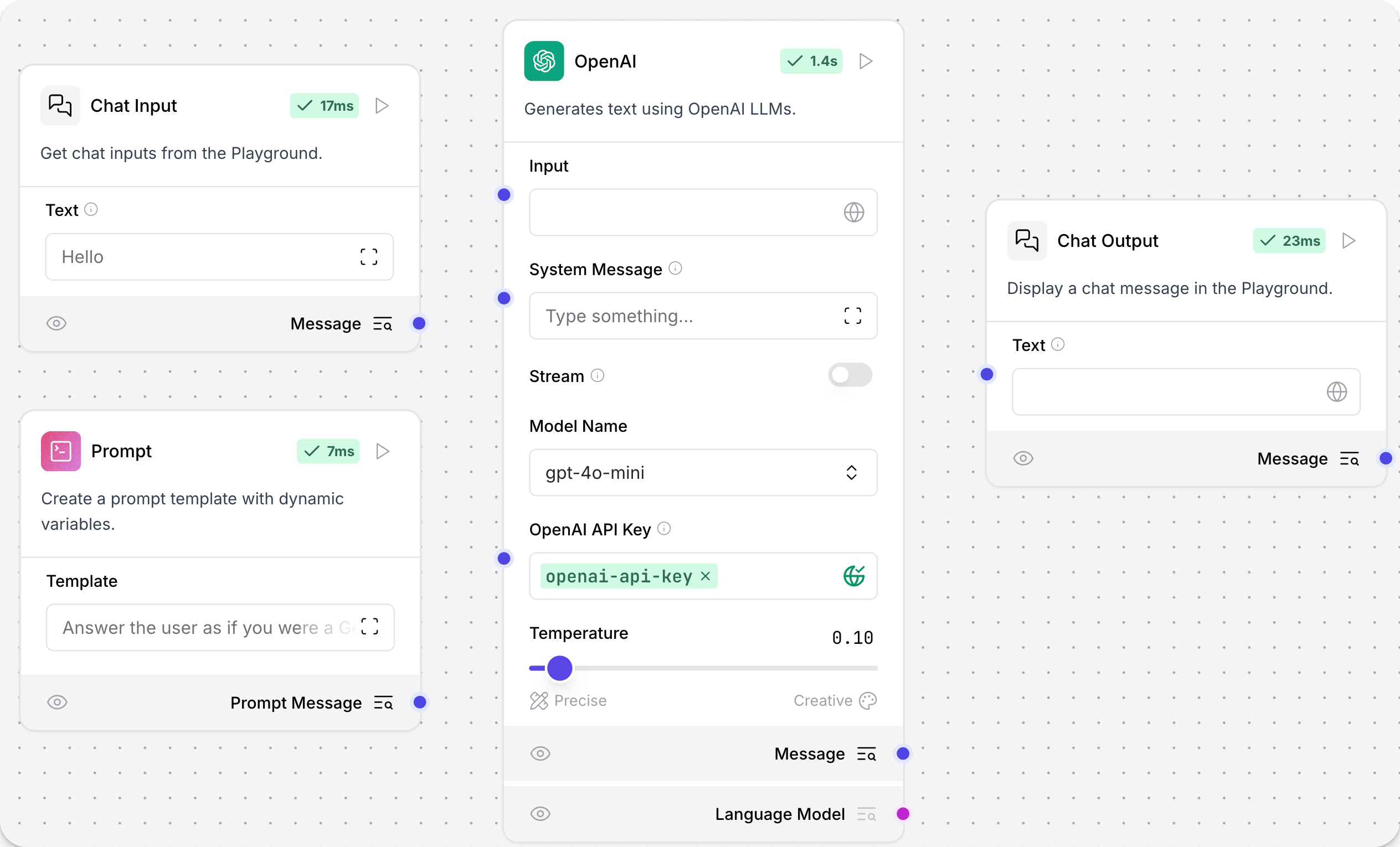
组件之间没有连接,它们不会相互作用。您希望数据通过组件之间的连接从 Chat Input(聊天输入)流向 Chat Output(聊天输出)。每个组件在其左侧接受输入,并在其右侧发送输出。将鼠标悬停在连接端口上,查看组件接受的数据类型。有关组件输入和输出的更多信息,请参阅组件概述。
- 要将 Chat Input(聊天输入)组件连接到 OpenAI 模型组件,点击蓝色 Message(消息)端口并拖动一条线到 OpenAI 模型组件的 Input(输入)端口。
- 要将 Prompt(提示)组件连接到 OpenAI 模型组件,点击蓝色 Prompt Message(提示消息)端口并拖动一条线到 OpenAI 模型组件的 System Message(系统消息)端口。
- 要将 OpenAI 模型组件连接到 Chat Output(聊天输出),点击蓝色 Text(文本)端口并拖动一条线到 Chat Output(聊天输出)组件的 Text(文本)端口。
您完成的基本提示流程应如下图所示
运行基本提示流程
将您的 OpenAI API 密钥添加到 OpenAI 模型组件中,并在 Prompt 组件中添加一个提示,以指导模型如何响应。
-
将您的凭据添加到 OpenAI 组件中。完成这些字段的最快方法是使用 Langflow 的全局变量。
- 在 OpenAI 组件的 OpenAI API Key 字段中,点击 Globe(地球仪)按钮,然后点击 Add New Variable(添加新变量)。或者,点击右上角您的用户图标,然后点击 Settings(设置)、Global Variables(全局变量),然后点击 Add New(添加新项)。
- 命名您的变量。将您的 OpenAI API 密钥(sk-...)粘贴到 Value 字段中。
- 在 Apply To Fields(应用于字段)字段中,选择 OpenAI API Key 字段,将此变量应用于所有 OpenAI Embeddings 组件。
-
要向 Prompt(提示)组件添加提示,点击 Template(模板)字段,然后输入您的提示。提示会指导机器人对输入的响应。如果不确定,可以使用
Answer the user as if you were a GenAI expert, enthusiastic about helping them get started building something fresh.(作为一名 GenAI 专家回答用户,热情地帮助他们开始构建新的东西。) -
点击 Playground(游乐场)开始聊天会话。
-
输入一个查询,然后确保机器人按照您在 Prompt(提示)组件中设置的提示进行响应。
您已成功地在 Langflow 工作区中使用 OpenAI 创建了一个聊天机器人应用。
向您的应用添加向量 RAG
您使用 Langflow 创建了一个聊天机器人应用,但让我们来尝试一个实验。
- 问机器人:
Who won the Oscar in 2024 for best movie?(2024 年奥斯卡最佳影片是谁?) - 机器人的回答与此类似
_10I'm sorry, but I don't have information on events or awards that occurred after_10October 2023, including the Oscars in 2024._10You may want to check the latest news or the official Oscars website_10for the most current information.
(抱歉,我没有 2023 年 10 月之后发生的事件或奖项信息,包括 2024 年的奥斯卡金像奖。您可能需要查看最新新闻或奥斯卡官方网站以获取最新信息。)嗯,这很不幸,但您可以通过检索增强生成 (RAG) 加载更多更新的数据。
向量 RAG 允许您加载自己的数据并与之聊天,从而解锁您的聊天机器人应用更广泛的可能性。
使用 Astra DB 组件添加向量 RAG
在基本提示流程的基础上,使用 Astra DB Vector Store(Astra DB 向量存储)组件向您的聊天机器人应用添加向量 RAG。
向您的基本提示流程添加文档摄取,并使用 Astra DB 组件作为向量存储。
如果您不想创建空白流程,可以点击 New Flow(新建流程),然后选择 Vector RAG(向量 RAG)以获取预构建的流程。
完成向基本提示流程添加向量 RAG 后将如下图所示
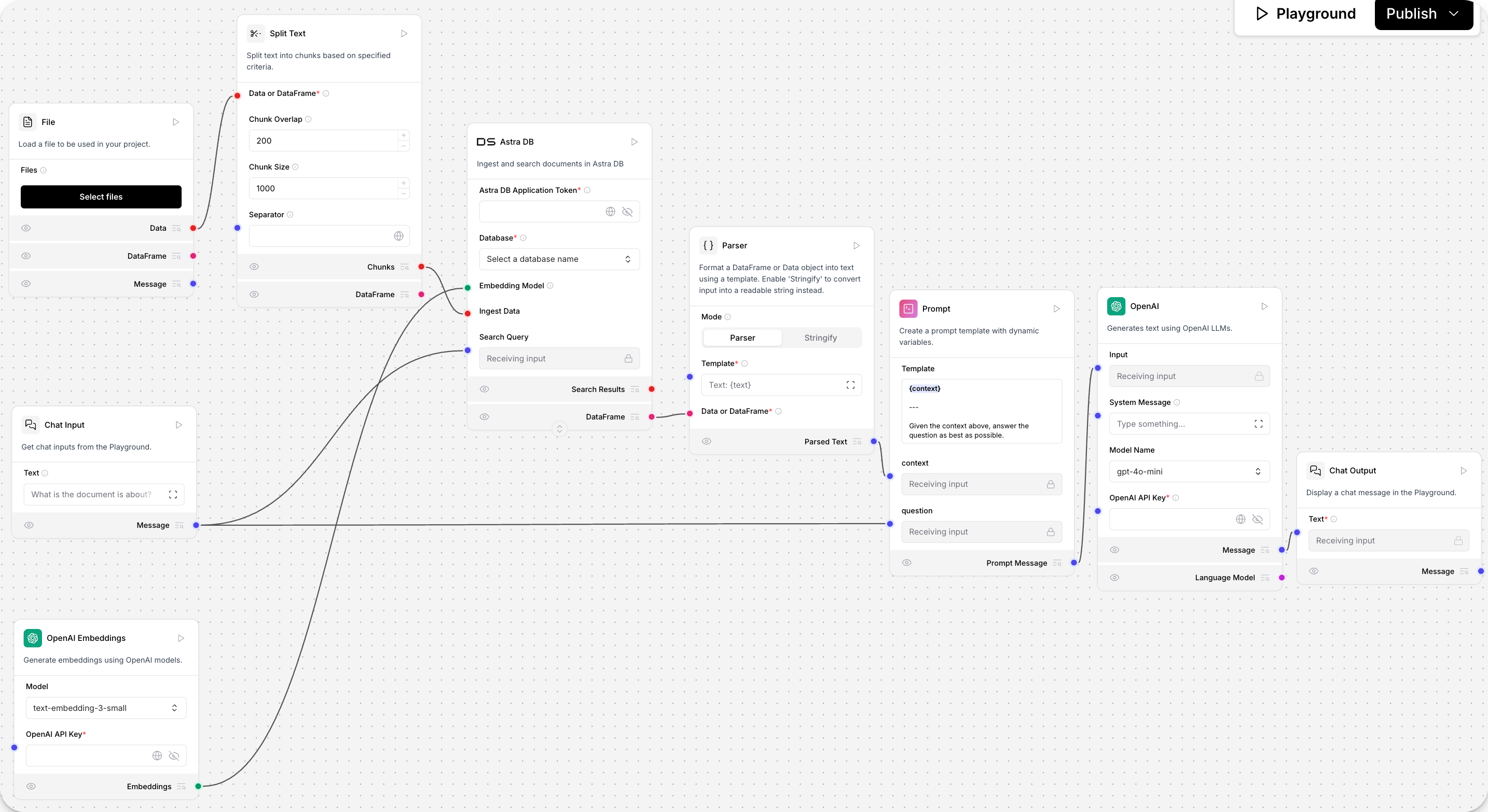
要构建此流程,请按照以下步骤操作
- 双击连接线断开 Chat Input(聊天输入)组件与 OpenAI 组件的连接。
- 点击 Vector Stores(向量存储),选择 Astra DB 组件,然后将其拖动到画布上。Astra DB vector store(Astra DB 向量存储)组件连接到您的 Astra DB 数据库。
- 点击 Data(数据),选择 File(文件)组件,然后将其拖动到画布上。File(文件)组件从您的本地机器加载文件。
- 点击 Processing(处理),选择 Split Text(分割文本)组件,然后将其拖动到画布上。Split Text(分割文本)组件将加载的文本分割成更小的块。
- 点击 Processing(处理),选择 Parser(解析器)组件,然后将其拖动到画布上。Parser(解析器)组件将来自 Astra DB 组件的数据转换为纯文本。
- 点击 Embeddings(嵌入),选择 OpenAI Embeddings(OpenAI 嵌入)组件,然后将其拖动到画布上。OpenAI Embeddings(OpenAI 嵌入)组件为用户的输入生成嵌入,这些嵌入将与数据库中的向量数据进行比较。
- 将新组件连接到现有流程中,使您的流程如下图所示
-
配置 Astra DB 组件。
- 在 Astra DB Application Token(Astra DB 应用令牌)字段中,添加您的 Astra DB 应用令牌。该组件将连接到您的数据库,并使用现有数据库和集合填充菜单。
- 选择您的 Database(数据库)。如果您没有集合,选择 New database(新建数据库)。填写 Name(名称)、Cloud provider(云提供商)和 Region(区域)字段,然后点击 Create(创建)。数据库创建需要几分钟时间。
- 选择您的 Collection(集合)。集合在您的 Astra DB 部署中创建,用于存储向量数据。
信息如果您选择了一个通过 Astra 的向量化服务嵌入 NVIDIA 的集合,则 Embedding Model(嵌入模型)端口将被移除,因为您已经使用 NVIDIA
NV-Embed-QA模型为该集合生成了嵌入。该组件将从集合中获取数据,并使用相同的嵌入进行查询。 -
如果您没有集合,请在该组件内创建一个新集合。
-
选择 New collection(新建集合)。
-
填写 Name(名称)、Embedding generation method(嵌入生成方法)、Embedding model(嵌入模型)和 Dimensions(维度)字段,然后点击 Create(创建)。
您选择的 Embedding generation method(嵌入生成方法)和 Embedding model(嵌入模型)取决于您是想使用通过 Astra 的向量化服务由提供商生成的嵌入,还是使用 Langflow 中的组件生成的嵌入。
- 要使用通过 Astra 的向量化服务由提供商生成的嵌入,请从 Embedding generation method(嵌入生成方法)下拉菜单中选择方法,然后从 Embedding model(嵌入模型)下拉菜单中选择模型。
- 要使用 Langflow 中组件生成的嵌入,请在 Embedding generation method(嵌入生成方法)和 Embedding model(嵌入模型)字段中都选择 Bring your own(自带)。在此入门项目中,嵌入方法和模型的选项是连接到 Astra DB 组件的 OpenAI Embeddings 组件。
- Dimensions(维度)值必须与您的集合的维度匹配。如果您使用通过 Astra 的向量化服务生成的嵌入,此字段不是必需的。您可以在您的 Astra DB 部署中的 Collection(集合)中找到此值。
有关更多信息,请参阅 DataStax Astra DB Serverless 文档。
-
如果您使用了 Langflow 的全局变量功能,RAG 应用流程组件已配置好必要的凭据。
运行带有检索上下文的聊天机器人
- 修改 Prompt(提示)组件,使其包含
{user_question}和{context}两个变量。{context}变量为机器人提供了除 LLM 训练数据之外的额外上下文来回答{user_question}。
_10Given the context_10{context}_10Answer the question_10{user_question}
- (给定上下文:{context},回答问题:{user_question})在 File(文件)组件中,从您的本地机器上传一个包含您要摄取到 Astra DB 组件数据库的数据的文本文件。本例上传了一个关于奥斯卡获奖者的最新 CSV 文件。
- 点击 Playground(游乐场)开始聊天会话。
- 问机器人:
Who won the Oscar in 2024 for best movie?(2024 年奥斯卡最佳影片是谁?) - 机器人的回答应与此类似
_10The Oscar for Best Picture in 2024 was awarded to "Oppenheimer,"_10produced by Emma Thomas, Charles Roven, and Christopher Nolan.
(2024 年的奥斯卡最佳影片颁给了《奥本海默》,由 Emma Thomas、Charles Roven 和 Christopher Nolan 制作。)添加 Astra DB 向量存储使您的聊天机器人能够了解最新的 2024 年信息。您已成功使用 Astra DB 组件向您的聊天机器人应用添加了 RAG。
下一步
本示例使用了电影数据,但 RAG 模式可用于您想要加载并与之聊天的任何数据。
将 Astra DB 数据库变成 Agent 用于做出决策的大脑。
将此流程发布为 API 并从您的外部应用程序调用它。
有关 Astra DB 组件的更多信息,请参阅 Astra DB vector store(Astra DB 向量存储)。