Langflow 中的嵌入模型
嵌入模型将文本转换为数值向量。这些嵌入捕获输入文本的语义含义,并使 LLM 能够理解上下文。
有关参数的更多信息,请参阅特定组件的文档。
在流程中使用嵌入模型组件
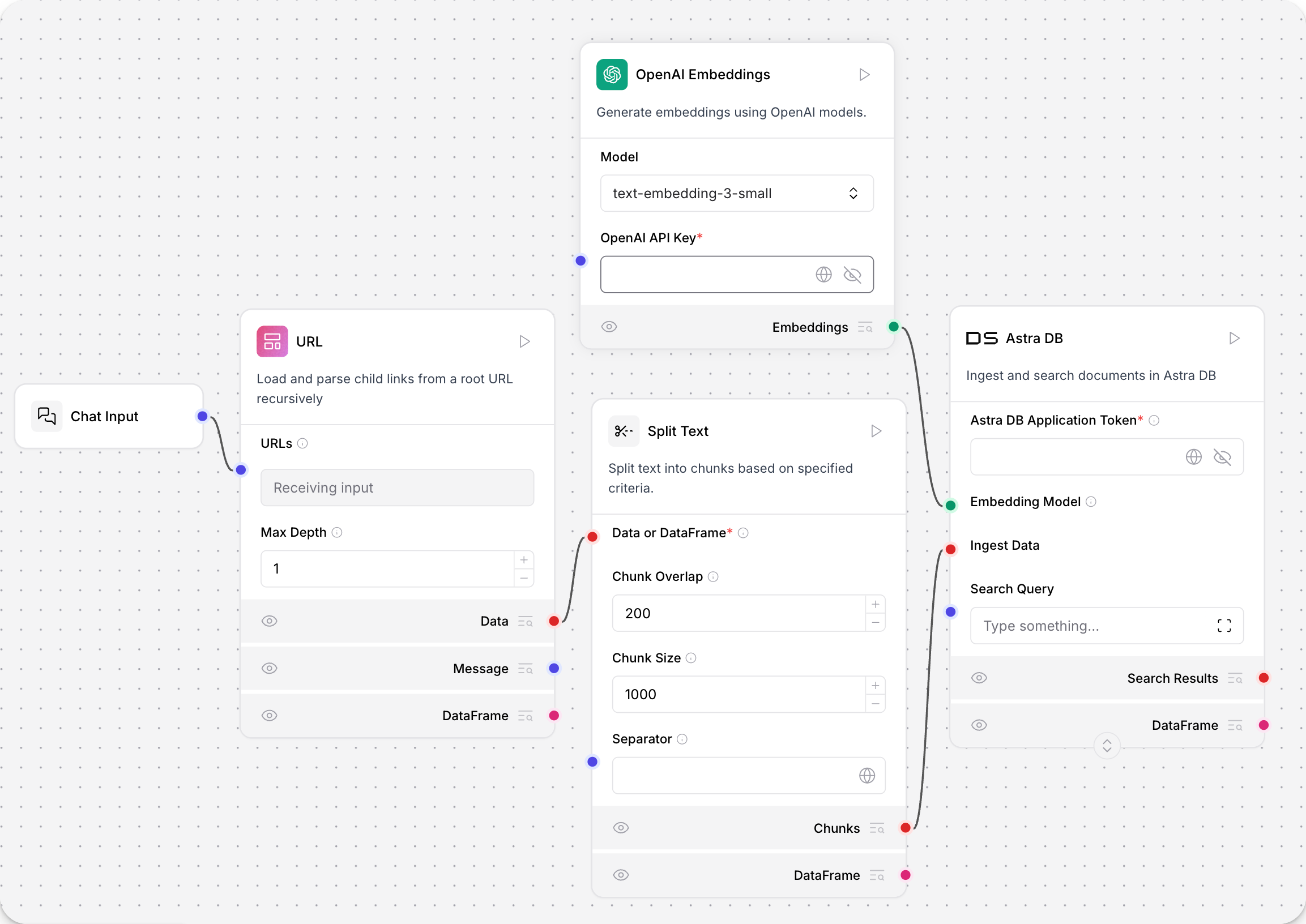
在此文档摄取流程示例中,OpenAI 嵌入模型连接到向量数据库。该组件将文本块转换为向量并将其存储在向量数据库中。向量化数据可用于支持 AI 工作负载,例如聊天机器人、相似性搜索和代理。
此嵌入组件使用 OpenAI API 密钥进行身份验证。有关身份验证的更多信息,请参阅特定嵌入组件的文档。
AI/ML
此组件使用 AI/ML API 生成嵌入。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| model_name | 字符串 | 要使用的 AI/ML 嵌入模型的名称。 |
| aiml_api_key | SecretString | 用于 AI/ML 服务身份验证所需的 API 密钥。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| embeddings | 嵌入 | 用于生成嵌入的 AIMLEmbeddingsImpl 实例。 |
Amazon Bedrock 嵌入
此组件用于从 Amazon Bedrock 加载嵌入模型。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| credentials_profile_name | 字符串 | ~/.aws/credentials 或 ~/.aws/config 中包含访问密钥或角色信息的 AWS 凭证配置文件的名称。 |
| model_id | 字符串 | 要调用的模型的 ID,例如 amazon.titan-embed-text-v1。这等同于 list-foundation-models API 中的 modelId 属性。 |
| endpoint_url | 字符串 | 设置特定服务终端节点而非默认 AWS 终端节点的 URL。 |
| region_name | 字符串 | 要使用的 AWS 区域,例如 us-west-2。如果未提供,则回退到 AWS_DEFAULT_REGION 环境变量或 ~/.aws/config 中指定的区域。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| embeddings | 嵌入 | 用于使用 Amazon Bedrock 生成嵌入的实例。 |
Astra DB vectorize
此组件自 Langflow 1.1.2 版本起已弃用。请改用Astra DB 向量存储组件。
将此组件连接到 Astra DB 向量存储组件的 Embeddings 端口以生成嵌入。
此组件要求您的 Astra DB 数据库具有使用 vectorize 嵌入提供程序集成的集合。有关更多信息和说明,请参阅嵌入生成。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| provider | 嵌入提供程序 | 要使用的嵌入提供程序。 |
| model_name | 模型名称 | 要使用的嵌入模型。 |
| authentication | 身份验证 | Astra 中存储您的 vectorize 嵌入提供程序凭证的 API 密钥的名称。(如果使用Astra 托管的嵌入提供程序,则不需要。) |
| provider_api_key | 提供程序 API 密钥 | 作为 authentication 的替代方案,直接提供您的嵌入提供程序凭证。 |
| model_parameters | 模型参数 | 其他模型参数。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| embeddings | 嵌入 | 用于使用 Astra vectorize 生成嵌入的实例。 |
Azure OpenAI 嵌入
此组件使用 Azure OpenAI 模型生成嵌入。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| 模型 | 字符串 | 要使用的模型的名称。默认值:text-embedding-3-small。 |
| Azure 终端节点 | 字符串 | 您的 Azure 终端节点,包括资源,例如 https://example-resource.azure.openai.com/。 |
| 部署名称 | 字符串 | 部署的名称。 |
| API 版本 | 字符串 | 要使用的 API 版本,选项包括各种日期。 |
| API 密钥 | 字符串 | 访问 Azure OpenAI 服务所需的 API 密钥。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| embeddings | 嵌入 | 用于使用 Azure OpenAI 生成嵌入的实例。 |
Cloudflare Workers AI 嵌入
此组件使用 Cloudflare Workers AI 模型生成嵌入。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| account_id | Cloudflare 账户 ID | 查找您的 Cloudflare 账户 ID. |
| api_token | Cloudflare API token | 创建 API token. |
| model_name | 模型名称 | 支持模型的列表. |
| strip_new_lines | 剥离换行符 | 是否从输入文本中剥离换行符。 |
| batch_size | 批量大小 | 每个批次中要嵌入的文本数量。 |
| api_base_url | Cloudflare API 基础 URL | Cloudflare API 的基础 URL。 |
| headers | 头部 | 其他请求头部。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embeddings | 嵌入 | 用于使用 Cloudflare Workers 生成嵌入的实例。 |
Cohere 嵌入
此组件用于从 Cohere 加载嵌入模型。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| cohere_api_key | 字符串 | 用于与 Cohere 服务进行身份验证所需的 API 密钥。 |
| model | 字符串 | 用于嵌入文本文档和执行查询的语言模型。默认值:embed-english-v2.0。 |
| truncate | 布尔值 | 是否截断输入文本以适应模型的约束。默认值:False。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| embeddings | 嵌入 | 用于使用 Cohere 生成嵌入的实例。 |
嵌入相似度
此组件计算两个嵌入向量之间选定形式的相似度。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embedding_vectors | 嵌入向量 | 包含恰好两个带有嵌入向量的数据对象用于比较的列表。 |
| similarity_metric | 相似度度量 | 选择要使用的相似度度量。选项:"余弦相似度", "欧氏距离", "曼哈顿距离"。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| similarity_data | 相似度数据 | 包含计算出的相似度分数和附加信息的数据对象。 |
Google 生成式 AI 嵌入
此组件使用来自 langchain-google-genai 包的 GoogleGenerativeAIEmbeddings 类连接到 Google 的生成式 AI 嵌入服务。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| api_key | API 密钥 | 用于访问 Google 生成式 AI 服务的秘密 API 密钥。必需。 |
| model_name | 模型名称 | 要使用的嵌入模型的名称。默认值:"models/text-embedding-004"。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embeddings | 嵌入 | 构建的 GoogleGenerativeAIEmbeddings 对象。 |
Hugging Face 嵌入
此组件自 Langflow 1.0.18 版本起已弃用。请改用Hugging Face 嵌入推理组件。
此组件从 HuggingFace 加载嵌入模型。
使用此组件使用本地下载的 Hugging Face 模型生成嵌入。确保您有足够的计算资源来运行这些模型。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| 缓存文件夹 | 缓存文件夹 | 缓存 HuggingFace 模型的文件夹路径。 |
| 编码参数 | 编码参数 | 编码过程的其他参数。 |
| 模型参数 | 模型参数 | 模型的其他参数。 |
| 模型名称 | 模型名称 | 要使用的 HuggingFace 模型的名称。 |
| 多进程 | 多进程 | 是否使用多个进程。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embeddings | 嵌入 | 生成的嵌入。 |
Hugging Face 嵌入推理
此组件使用 Hugging Face 推理 API 模型生成嵌入,并且需要 Hugging Face API token 进行身份验证。本地推理模型不需要 API 密钥。
使用此组件使用 Hugging Face 托管模型创建嵌入,或连接到您自己的本地托管模型。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| API 密钥 | API 密钥 | 用于访问 Hugging Face 推理 API 的 API 密钥。 |
| API URL | API URL | Hugging Face 推理 API 的 URL。 |
| 模型名称 | 模型名称 | 用于嵌入的模型的名称。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embeddings | 嵌入 | 生成的嵌入。 |
将 Hugging Face 组件连接到本地嵌入模型
要在本地运行嵌入推理,请参阅 HuggingFace 文档。
要将本地 Hugging Face 模型连接到 Hugging Face 嵌入推理组件并在流程中使用它,请按照以下步骤操作
- 创建一个向量存储 RAG 流程。此流程中有两个嵌入模型,您可以用 Hugging Face 嵌入推理组件替换它们。
- 将两个 OpenAI 嵌入模型组件替换为 Hugging Face 模型组件。
- 将两个 Hugging Face 组件连接到 Astra DB 向量存储组件的 Embeddings 端口。
- 在 Hugging Face 组件中,将 Inference Endpoint 字段设置为本地推理模型的 URL。本地推理不需要 API 密钥字段。
- 运行流程。本地推理模型为输入文本生成嵌入。
IBM watsonx 嵌入
此组件使用 IBM watsonx.ai 基础模型生成文本。
要使用 IBM watsonx.ai 嵌入组件,请在流程中用 IBM watsonx.ai 组件替换嵌入组件。
文档处理流程示例如下所示
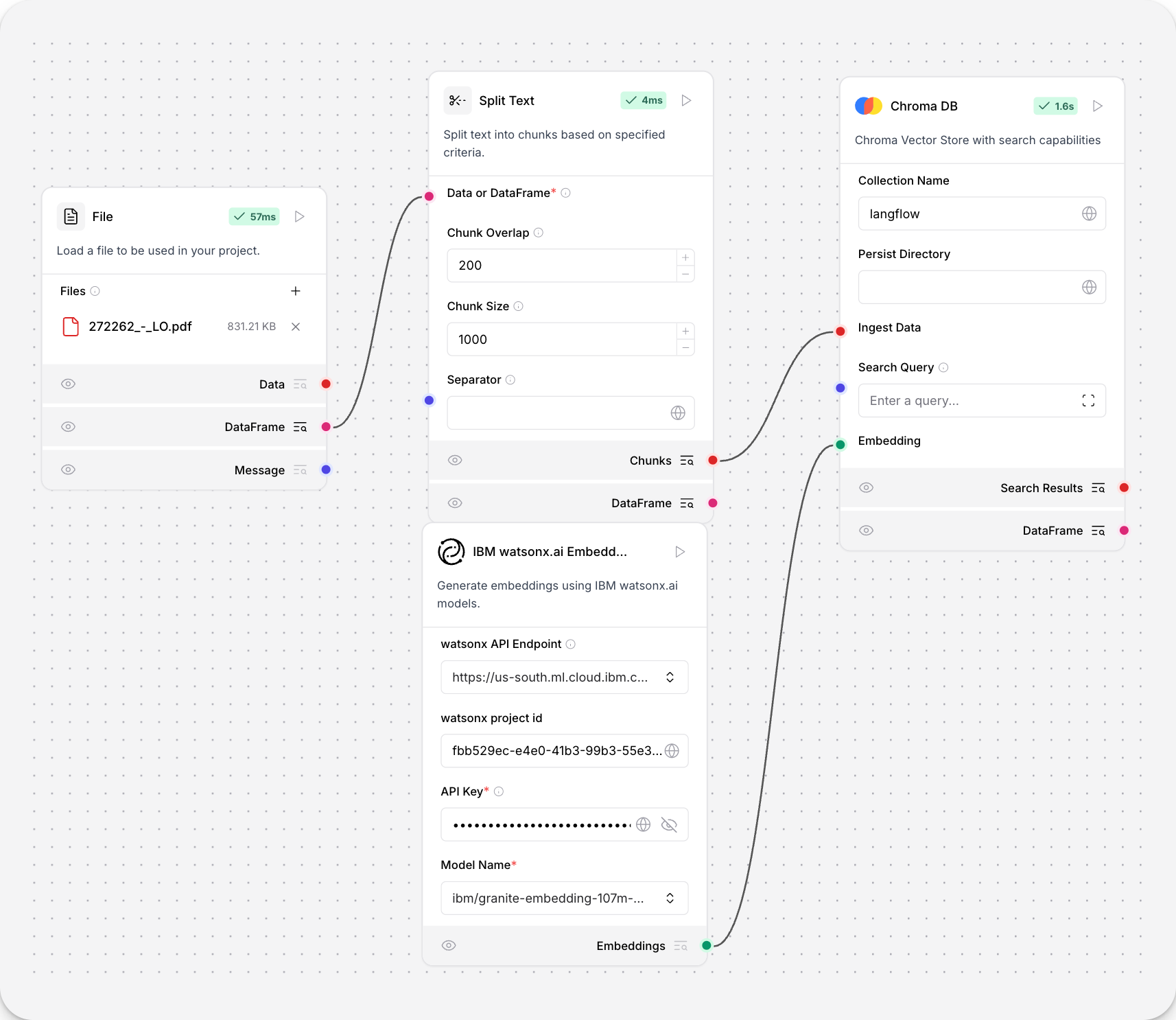
此流程从本地存储加载 PDF 文件,并将文本分割成块。
IBM watsonx 嵌入组件将文本块转换为嵌入,然后将其存储在 Chroma DB 向量存储中。
API 终端节点、项目 ID、API 密钥和模型名称的值可在您的 IBM watsonx.ai 部署中找到。有关更多信息,请参阅Langchain 文档。
默认模型
该组件支持具有以下向量维度的多个默认模型
sentence-transformers/all-minilm-l12-v2:384 维嵌入ibm/slate-125m-english-rtrvr-v2:768 维嵌入ibm/slate-30m-english-rtrvr-v2:768 维嵌入intfloat/multilingual-e5-large:1024 维嵌入
当您提供 API 终端节点和凭证时,该组件会自动从您的 watsonx.ai 实例获取和更新可用模型的列表。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| url | watsonx API 终端节点 | API 的基础 URL。 |
| project_id | watsonx 项目 ID | 您的 watsonx.ai 实例的项目 ID。 |
| api_key | API 密钥 | 用于模型的 API 密钥。 |
| model_name | 模型名称 | 要使用的嵌入模型的名称。 |
| truncate_input_tokens | 截断输入令牌 | 要处理的最大令牌数。默认值:200。 |
| input_text | 在输出中包含原始文本 | 确定输出中是否包含原始文本。默认值:True。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embeddings | 嵌入 | 用于使用 watsonx.ai 生成嵌入的实例。 |
LM Studio 嵌入
此组件使用 LM Studio 模型生成嵌入。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| model | 模型 | 用于生成嵌入的 LM Studio 模型。 |
| base_url | LM Studio 基础 URL | LM Studio API 的基础 URL。 |
| api_key | LM Studio API 密钥 | 用于与 LM Studio 进行身份验证的 API 密钥。 |
| temperature | 模型温度 | 模型的温度设置。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embeddings | 嵌入 | 生成的嵌入。 |
MistralAI
此组件使用 MistralAI 模型生成嵌入。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| model | 字符串 | 要使用的 MistralAI 模型。默认值:"mistral-embed"。 |
| mistral_api_key | SecretString | 用于与 MistralAI 进行身份验证的 API 密钥。 |
| max_concurrent_requests | 整数 | 最大并发 API 请求数。默认值:64。 |
| max_retries | 整数 | 失败请求的最大重试次数。默认值:5。 |
| timeout | 整数 | 请求超时时间(秒)。默认值:120。 |
| endpoint | 字符串 | 自定义 API 终端节点 URL。默认值:https://api.mistral.ai/v1/。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| embeddings | 嵌入 | 用于生成嵌入的 MistralAIEmbeddings 实例。 |
NVIDIA
此组件使用 NVIDIA 模型生成嵌入。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| model | 字符串 | 用于嵌入的 NVIDIA 模型,例如 nvidia/nv-embed-v1。 |
| base_url | 字符串 | NVIDIA API 的基础 URL。默认值:https://integrate.api.nvidia.com/v1。 |
| nvidia_api_key | SecretString | 用于与 NVIDIA 服务进行身份验证的 API 密钥。 |
| temperature | 浮点数 | 用于生成嵌入的模型温度。默认值:0.1。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| embeddings | 嵌入 | 用于生成嵌入的 NVIDIAEmbeddings 实例。 |
Ollama 嵌入
此组件使用 Ollama 模型生成嵌入。
有关 Ollama 嵌入模型的列表,请参阅Ollama 文档。
要在流程中使用此组件,请将 Langflow 连接到您本地运行的 Ollama 服务器并选择一个嵌入模型。
- 在 Ollama 组件的 Ollama 基础 URL 字段中,输入本地运行的 Ollama 服务器的地址。此值在 Ollama 中设置为
OLLAMA_HOST环境变量。默认基础 URL 为http://127.0.0.1:11434。 - 要刷新服务器的模型列表,请点击.
- 在 Ollama 模型字段中,选择一个嵌入模型。此示例使用
all-minilm:latest。 - 将 Ollama 嵌入组件连接到流程。例如,此流程将运行
all-minilm:latest嵌入模型的本地 Ollama 服务器连接到 Chroma DB 向量存储,以为分割文本生成嵌入。
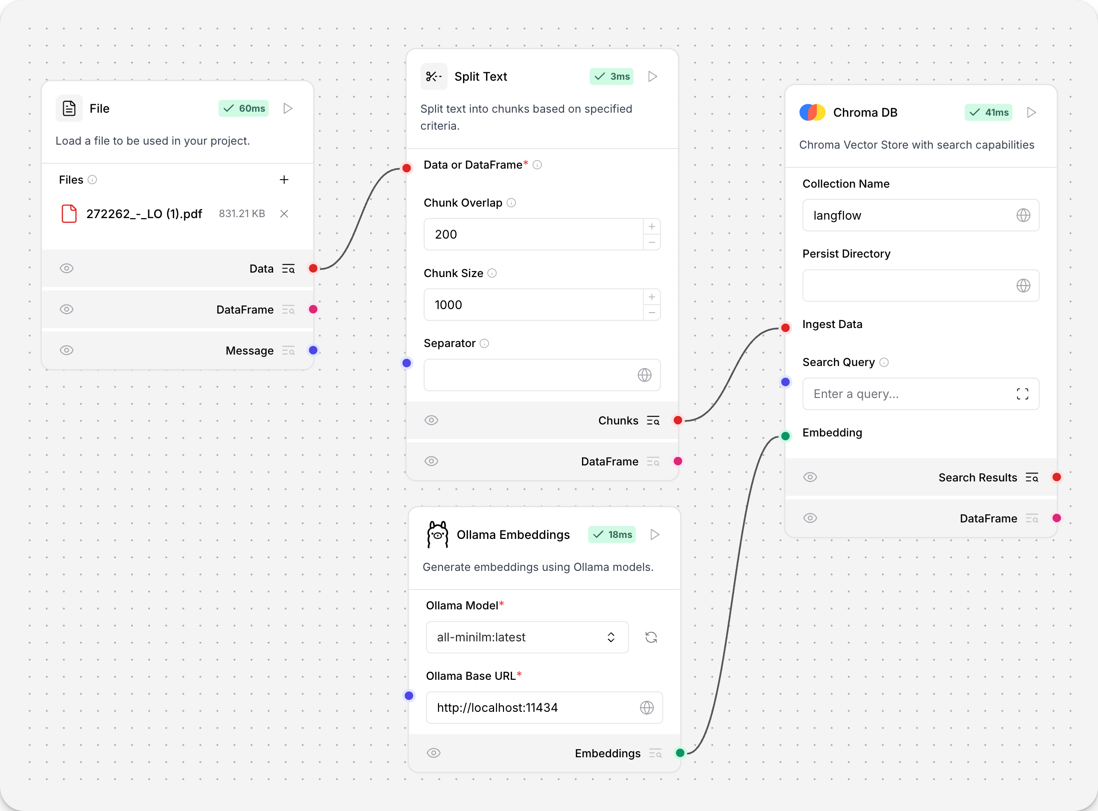
有关更多信息,请参阅Ollama 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| Ollama 模型 | 字符串 | 要使用的 Ollama 模型的名称。默认值:llama2。 |
| Ollama 基础 URL | 字符串 | Ollama API 的基础 URL。默认值:https://:11434。 |
| 模型温度 | 浮点数 | 模型的温度参数。调整生成嵌入中的随机性。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| embeddings | 嵌入 | 用于使用 Ollama 生成嵌入的实例。 |
OpenAI 嵌入
此组件用于从 OpenAI 加载嵌入模型。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| OpenAI API 密钥 | 字符串 | 用于访问 OpenAI API 的 API 密钥。 |
| 默认头部 | 字典 | HTTP 请求的默认头部。 |
| 默认查询 | NestedDict | HTTP 请求的默认查询参数。 |
| 允许的特殊令牌 | 列表 | 允许处理的特殊令牌。默认值:[]。 |
| 禁止的特殊令牌 | 列表 | 禁止处理的特殊令牌。默认值:["all"]。 |
| 块大小 | 整数 | 处理的块大小。默认值:1000。 |
| 客户端 | Any | 用于发出请求的 HTTP 客户端。 |
| 部署 | 字符串 | 模型的部署名称。默认值:text-embedding-3-small。 |
| 嵌入上下文长度 | 整数 | 嵌入上下文的长度。默认值:8191。 |
| 最大重试次数 | 整数 | 失败请求的最大重试次数。默认值:6。 |
| 模型 | 字符串 | 要使用的模型的名称。默认值:text-embedding-3-small。 |
| 模型参数 | NestedDict | 模型的其他关键字参数。 |
| OpenAI API 基础 | 字符串 | OpenAI API 的基础 URL。 |
| OpenAI API 类型 | 字符串 | OpenAI API 的类型。 |
| OpenAI API 版本 | 字符串 | OpenAI API 的版本。 |
| OpenAI 组织 | 字符串 | 与 API 密钥关联的组织。 |
| OpenAI 代理 | 字符串 | 请求的代理服务器。 |
| 请求超时 | 浮点数 | HTTP 请求的超时时间。 |
| 显示进度条 | 布尔值 | 是否显示处理进度条。默认值:False。 |
| 跳过空值 | 布尔值 | 是否跳过空输入。默认值:False。 |
| 启用 TikToken | 布尔值 | 是否启用 TikToken。默认值:True。 |
| TikToken 模型名称 | 字符串 | TikToken 模型的名称。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| embeddings | 嵌入 | 用于使用 OpenAI 生成嵌入的实例。 |
文本嵌入器
此组件使用指定的嵌入模型为给定消息生成嵌入。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embedding_model | 嵌入模型 | 用于生成嵌入的嵌入模型。 |
| message | 消息 | 要生成嵌入的消息。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embeddings | 嵌入数据 | 包含原始文本及其嵌入向量的数据对象。 |
VertexAI 嵌入
此组件是 Google Vertex AI 嵌入 API 的包装器。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| credentials | 凭证 | 要使用的默认自定义凭证。 |
| location | 字符串 | 进行 API 调用时使用的默认位置。默认值:us-central1。 |
| max_output_tokens | 整数 | 令牌限制决定了单个提示的最大文本输出量。默认值:128。 |
| model_name | 字符串 | Vertex AI 大型语言模型的名称。默认值:text-bison。 |
| project | 字符串 | 进行 Vertex API 调用时使用的默认 GCP 项目。 |
| request_parallelism | 整数 | 允许向 VertexAI 模型发出的请求的并行度。默认值:5。 |
| temperature | 浮点数 | 调整文本生成中的随机性程度。应为非负值。默认值:0。 |
| top_k | 整数 | 模型如何选择用于输出的令牌。下一个令牌从前 k 个令牌中选择。默认值:40。 |
| top_p | 浮点数 | 从概率最高到最低选择令牌,直到它们的概率总和超过前 p 值。默认值:0.95。 |
| tuned_model_name | 字符串 | 微调模型的名称。如果提供,则忽略 model_name。 |
| verbose | 布尔值 | 此参数控制输出的详细程度。设置为 True 时,它会打印链的内部状态以帮助调试。默认值:False。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| embeddings | 嵌入 | 用于使用 VertexAI 生成嵌入的实例。 |