Langflow 中的向量存储组件
向量数据库存储向量数据,为聊天机器人和检索增强生成等 AI 工作负载提供支持。
向量数据库组件用于建立与现有向量数据库的连接,或创建内存向量存储来存储和检索向量数据。
向量数据库组件与记忆组件不同,后者专门用于存储和检索来自外部数据库的聊天消息。
在流程中使用向量存储组件
本示例使用 Astra DB 向量存储组件。您的向量存储组件的参数和认证方式可能有所不同,但文档摄取工作流程是相同的。文档从本地机器加载并分块。Astra DB 向量存储使用连接的模型组件生成嵌入,并将它们存储在连接的 Astra DB 数据库中。
然后可以检索这些向量数据,用于检索增强生成等工作负载。
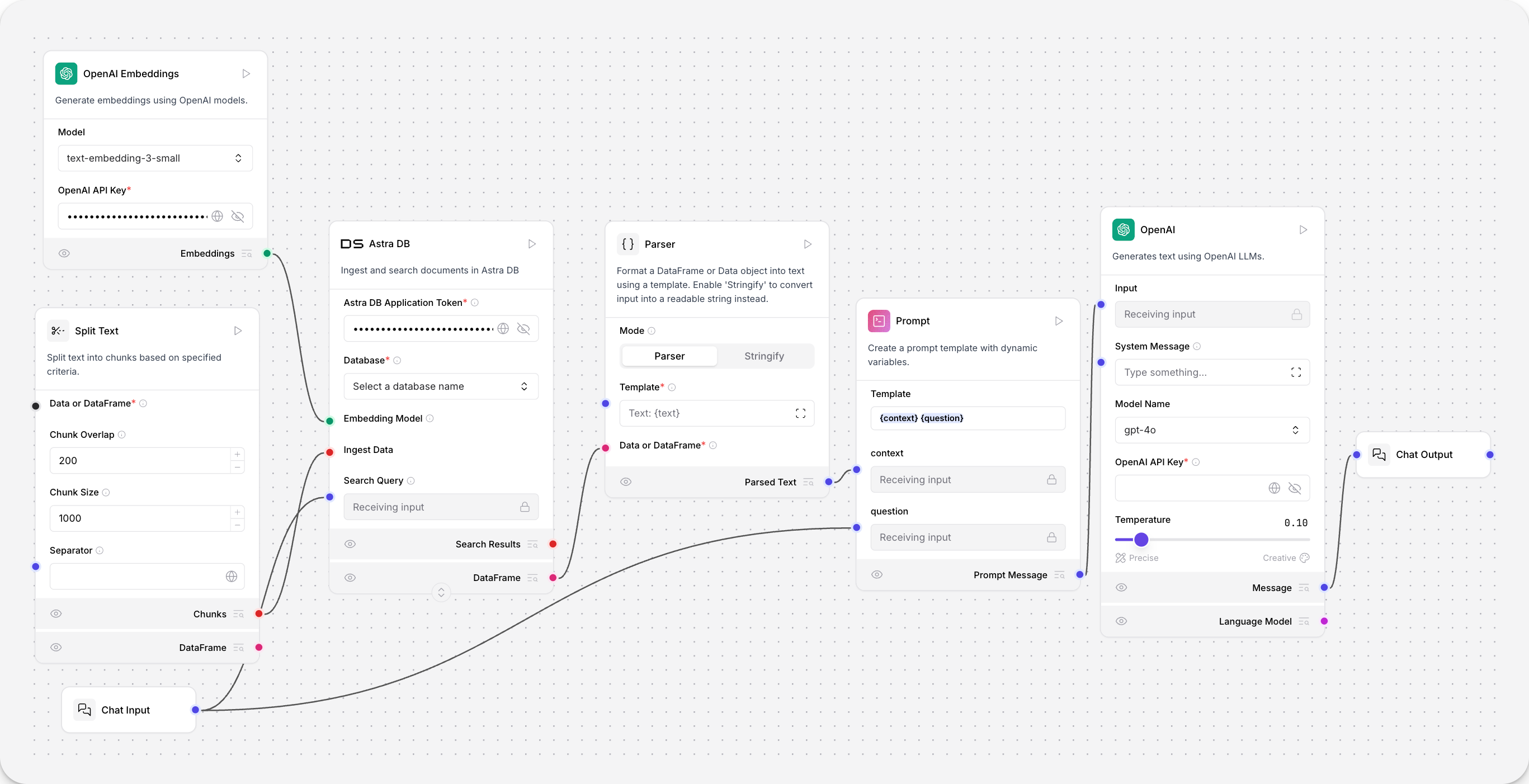
用户的聊天输入被嵌入并与文档摄取过程中嵌入的向量进行比较,以进行相似性搜索。结果从向量数据库组件输出为数据对象并解析为文本。此文本填充提示组件中的{context}变量,后者为Open AI 模型组件的响应提供信息。
或者,将向量数据库组件的检索器端口连接到检索器工具,然后再连接到Agent组件。这使得 Agent 能够将您的向量数据库用作工具,并根据可用数据做出决策。

Astra DB 向量存储
此组件使用 Astra DB 实现具有搜索功能的向量存储。
有关更多信息,请参阅DataStax 文档。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| token | Astra DB 应用 token | 用于访问 Astra DB 的认证 token。 |
| environment | 环境 | Astra DB API 端点的环境。例如,dev 或 prod。 |
| database_name | 数据库 | Astra DB 实例的数据库名称。 |
| api_endpoint | Astra DB API 端点 | Astra DB 实例的 API 端点。这将覆盖数据库选择。 |
| collection_name | 集合 | 向量存储在 Astra DB 中的集合名称。 |
| keyspace | 键空间 | Astra DB 中用于集合的可选键空间。 |
| embedding_choice | 嵌入模型或 Astra Vectorize | 选择一个嵌入模型或使用 Astra vectorize。 |
| embedding_model | 嵌入模型 | 指定嵌入模型。Astra vectorize 集合不需要此参数。 |
| number_of_results | 搜索结果数量 | 要返回的搜索结果数量。默认值:4。 |
| search_type | 搜索类型 | 要使用的搜索类型。选项包括相似度、带分数阈值的相似度和MMR(最大边际相关性)。 |
| search_score_threshold | 搜索分数阈值 | 使用带分数阈值的相似度选项时,搜索结果的最低相似度分数阈值。 |
| advanced_search_filter | 搜索元数据过滤器 | 应用于搜索查询的可选过滤器字典。 |
| autodetect_collection | 自动检测集合 | 用于确定是否自动检测集合的布尔标志。 |
| content_field | 内容字段 | 用作向量存储文本内容字段的字段。 |
| deletion_field | 基于字段删除 | 提供此字段时,目标集合中元数据字段值与输入元数据字段值匹配的文档将在加载新数据之前被删除。 |
| ignore_invalid_documents | 忽略无效文档 | 用于确定在运行时是否忽略无效文档的布尔标志。 |
| astradb_vectorstore_kwargs | AstraDBVectorStore 参数 | AstraDBVectorStore 的其他可选参数字典。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | 配置了指定参数的 Astra DB 向量存储实例。 |
| search_results | 搜索结果 | 作为数据对象列表的相似性搜索结果。 |
生成嵌入
Astra DB 向量存储组件提供两种生成嵌入的方法。
-
嵌入模型:通过连接 Langflow 中的嵌入组件来使用您自己的嵌入模型。
-
Astra Vectorize:使用 Astra DB 内置的嵌入生成服务。创建新集合时,选择嵌入提供商和模型,包括 Datastax 托管的 NVIDIA
NV-Embed-QA模型。
嵌入模型的选择是在创建新集合时进行的,之后无法更改。
有关使用带嵌入模型的Astra DB 向量存储组件的示例,请参阅向量存储 RAG 入门项目。
有关更多信息,请参阅Astra DB Serverless 文档。
混合搜索
Astra DB 组件包含混合搜索功能,默认情况下启用。
与混合搜索相关的组件字段是搜索查询、词汇术语和重排序器。
- 搜索查询通过向量相似度查找结果。
- 词汇术语是以逗号分隔的关键词字符串,例如
features, data, attributes, characteristics。 - 重排序器是混合搜索中使用的重排序模型。重排序模型是
nvidia/llama-3.2-nv.reranker。
混合搜索执行向量相似度搜索和词汇搜索,比较两种搜索的结果,然后返回总体上最相关的结果。
要使用混合搜索,您的集合必须在创建时启用向量、词汇和重排序功能。在 AWS us-east-2 区域的数据库中创建集合时,默认情况下启用这些功能。有关更多信息,请参阅DataStax 文档。
要在 Astra DB 组件中使用混合搜索,请执行以下操作
- 单击新建流程 > RAG > 混合搜索 RAG。
- 在 OpenAI 模型组件中,添加您的 OpenAI API 密钥。
- 在 Astra DB 向量存储组件中,添加您的 Astra DB 应用 Token。
- 在数据库字段中,选择您的数据库。
- 在集合字段中,选择或创建一个启用混合搜索功能的集合。
- 在操场中,输入一个关于您数据的问题,例如
我的数据有哪些特征?您的查询被发送到两个组件:一个 OpenAI 模型组件和 Astra DB 向量数据库组件。OpenAI 组件包含一个用于根据您的输入创建词汇查询的提示
_10您是一个数据库查询规划器,接收用户请求,然后将其转换为针对相关主题内容的搜索。_10您应该将查询转换为_101. 一个用于针对 Lucene 文本分析器索引的关键词列表,不超过 4 个。严格使用单元词(unigrams)。_102. 一个用作 QA 嵌入引擎基础的问题。_10避免与用户主题相关的常见关键词。
- 要在 OpenAI 组件中查看 OpenAI 组件根据您的集合生成的关键词和问题,请在 OpenAI 组件中单击.
_101. 关键词:features, data, attributes, characteristics_102. 问题:我的数据中可以识别出哪些特征?
-
要查看从 OpenAI 组件的响应生成的DataFrame,请在结构化输出组件中单击。该 DataFrame 会传递给一个解析器组件,该组件将关键词列的内容解析为字符串。
此逗号分隔的词语字符串被传递给 Astra DB 组件的词汇术语端口。请注意,Astra DB 端口的搜索查询端口连接到步骤 6 中的聊天输入组件。此搜索查询被向量化,搜索查询和词汇术语内容都被发送到
find_and_rerank端点的重排序器。重排序器将向量搜索结果与词汇搜索的术语字符串进行比较。混合搜索的最高排名结果将返回到操场。
有关更多信息,请参阅DataStax 文档。
AstraDB 图向量存储
此组件使用 AstraDB 实现具有图功能的向量存储。有关更多信息,请参阅Astra DB Serverless 文档。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| collection_name | 集合名称 | 向量存储在 AstraDB 中的集合名称。必需。 |
| token | Astra DB 应用 token | 用于访问 AstraDB 的认证 token。必需。 |
| api_endpoint | API 端点 | AstraDB 服务的 API 端点 URL。必需。 |
| search_input | 搜索输入 | 用于相似性搜索的查询字符串。 |
| ingest_data | 摄取数据 | 要摄取到向量存储中的数据。 |
| namespace | 命名空间 | AstraDB 中用于集合的可选命名空间。 |
| embedding | 嵌入模型 | 要使用的嵌入模型。 |
| metric | 度量 | 向量比较的距离度量。选项包括“cosine”、“euclidean”、“dot_product”。 |
| setup_mode | 设置模式 | 设置向量存储的配置模式。选项包括“同步”、“异步”、“关闭”。 |
| pre_delete_collection | 预删除集合 | 用于确定在创建新集合之前是否删除现有集合的布尔标志。 |
| number_of_results | 结果数量 | 相似性搜索中返回的结果数量。默认值:4。 |
| search_type | 搜索类型 | 要使用的搜索类型。选项包括“相似度”、“图遍历”、“混合”。 |
| traversal_depth | 遍历深度 | 图遍历搜索的最大深度。默认值:1。 |
| search_score_threshold | 搜索分数阈值 | 搜索结果的最低相似度分数阈值。 |
| search_filter | 搜索元数据过滤器 | 应用于搜索查询的可选过滤器字典。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | 配置了指定参数的 Graph RAG 向量存储实例。 |
| search_results | 搜索结果 | 作为数据对象列表的相似性搜索结果。 |
Cassandra
此组件创建具有搜索功能的 Cassandra 向量存储。有关更多信息,请参阅Cassandra 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| database_ref | 字符串 | 数据库的连接点或 AstraDB 数据库 ID。 |
| username | 字符串 | 数据库的用户名(对于 AstraDB,留空)。 |
| token | SecretString | 数据库的用户密码或 AstraDB token。 |
| keyspace | 字符串 | 表键空间或 AstraDB 命名空间。 |
| table_name | 字符串 | 表名或 AstraDB 集合名。 |
| ttl_seconds | 整数 | 添加文本的生存时间(TTL)。 |
| batch_size | 整数 | 单个批次中处理的数据数量。 |
| setup_mode | 字符串 | 设置 Cassandra 表的配置模式。 |
| cluster_kwargs | 字典 | Cassandra 集群的其他关键字参数。 |
| search_query | 字符串 | 用于相似性搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据。 |
| embedding | 嵌入 | 要使用的嵌入函数。 |
| number_of_results | 整数 | 搜索中返回的结果数量。 |
| search_type | 字符串 | 要执行的搜索类型。 |
| search_score_threshold | 浮点数 | 搜索结果的最低相似度分数。 |
| search_filter | 字典 | 搜索查询的元数据过滤器。 |
| body_search | 字符串 | 文档文本搜索术语。 |
| enable_body_search | 布尔值 | 启用正文搜索的标志。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Cassandra | 配置了指定参数的 Cassandra 向量存储实例。 |
| search_results | 列表[数据] | 相似性搜索的结果,作为数据对象列表。 |
Cassandra 图向量存储
此组件实现具有搜索功能的 Cassandra 图向量存储。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| database_ref | 连接点 / Astra 数据库 ID | 数据库的连接点或 AstraDB 数据库 ID。必需。 |
| username | 用户名 | 数据库的用户名。对于 AstraDB,此字段留空。 |
| token | 密码 / AstraDB Token | 数据库的用户密码或 AstraDB token。必需。 |
| keyspace | 键空间 | 表键空间或 AstraDB 命名空间。必需。 |
| table_name | 表名 | 存储向量的表名或 AstraDB 集合名。必需。 |
| setup_mode | 设置模式 | 设置 Cassandra 表的配置模式。选项包括“同步”或“关闭”。默认值:“同步”。 |
| cluster_kwargs | 集群参数 | Cassandra 集群的其他可选关键字参数字典。 |
| search_query | 搜索查询 | 用于相似性搜索的查询字符串。 |
| ingest_data | 摄取数据 | 要摄取到向量存储中的数据列表。 |
| embedding | 嵌入 | 要使用的嵌入模型。 |
| number_of_results | 结果数量 | 相似性搜索中返回的结果数量。默认值:4。 |
| search_type | 搜索类型 | 要使用的搜索类型。选项包括“遍历”、“MMR 遍历”、“相似度”、“带分数阈值的相似度”或“MMR(最大边际相关性)”。默认值:“遍历”。 |
| depth | 遍历深度 | 要遍历的边的最大深度。用于“遍历”或“MMR 遍历”搜索类型。默认值:1。 |
| search_score_threshold | 搜索分数阈值 | 搜索结果的最低相似度分数阈值。用于“带分数阈值的相似度”搜索类型。 |
| search_filter | 搜索元数据过滤器 | 应用于搜索查询的可选过滤器字典。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | 配置了指定参数的 Cassandra 图向量存储实例。 |
| search_results | 搜索结果 | 作为数据对象列表的相似性搜索结果。 |
Chroma DB
此组件创建具有搜索功能的 Chroma 向量存储。
Chroma DB 组件创建一个用于实验和向量存储的临时向量数据库。
- 要在流程中使用此组件,请将其连接到输出数据或DataFrame的组件。本示例将URL组件中的文本进行分割,并使用连接的 OpenAI 嵌入组件计算嵌入。Chroma DB 默认计算嵌入,但您可以连接自己的嵌入模型,如本示例所示。
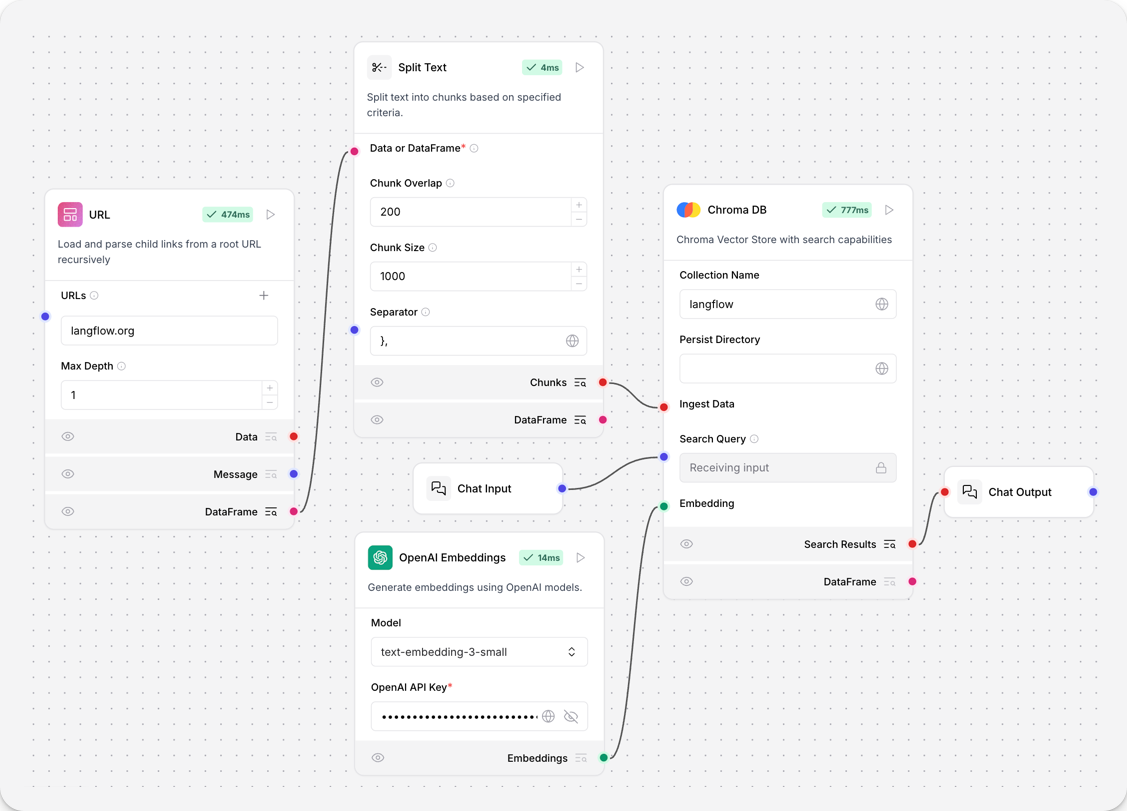
- 在 Chroma DB 组件中,在集合字段中,输入您的嵌入集合的名称。
- 可选地,要持久化 Chroma 数据库,请在持久化字段中输入一个目录来存储
chroma.sqlite3文件。本示例使用./chroma-db在 Langflow 运行的位置创建一个相对目录。 - 要将数据和嵌入加载到您的 Chroma 数据库中,请在 Chroma DB 组件中单击.
加载重复文档时,如果您想存储相同内容的多个副本,请在 Chroma DB 中启用允许重复选项;如果想自动去重,则禁用此选项。
- 要查看分割的数据,请在文本分割组件中单击.
- 要查询已加载的数据,请打开操场并查询您的数据库。您的输入将被转换为向量数据,并与存储的向量进行向量相似性搜索比较。
有关更多信息,请参阅Chroma 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| collection_name | 字符串 | Chroma 集合的名称。默认值:“langflow”。 |
| persist_directory | 字符串 | 持久化 Chroma 数据库的目录。 |
| search_query | 字符串 | 要在向量存储中搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据(数据对象列表)。 |
| embedding | 嵌入 | 用于向量存储的嵌入函数。 |
| chroma_server_cors_allow_origins | 字符串 | Chroma 服务器的 CORS 允许来源。 |
| chroma_server_host | 字符串 | Chroma 服务器的主机。 |
| chroma_server_http_port | 整数 | Chroma 服务器的 HTTP 端口。 |
| chroma_server_grpc_port | 整数 | Chroma 服务器的 gRPC 端口。 |
| chroma_server_ssl_enabled | 布尔值 | 为 Chroma 服务器启用 SSL。 |
| allow_duplicates | 布尔值 | 允许向量存储中存在重复文档。 |
| search_type | 字符串 | 要执行的搜索类型:“相似度”或“MMR”。 |
| number_of_results | 整数 | 搜索返回的结果数量。默认值:10。 |
| limit | 整数 | 当允许重复为False时,要比较的记录数量限制。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Chroma | Chroma 向量存储实例。 |
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |
Clickhouse
此组件实现具有搜索功能的 Clickhouse 向量存储。有关更多信息,请参阅Clickhouse 文档。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| host | 主机名 | Clickhouse 服务器主机名。必需。默认值:“localhost”。 |
| port | port | Clickhouse 服务器端口。必需。默认值:8123。 |
| database | database | Clickhouse 数据库名称。必需。 |
| table | 表名 | Clickhouse 表名。必需。 |
| username | ClickHouse 用户名。 | 用于认证的用户名。必需。 |
| password | 用户名的密码。 | 用于认证的密码。必需。 |
| index_type | index_type | 索引类型。选项包括“annoy”和“vector_similarity”。默认值:“annoy”。 |
| metric | metric | 计算距离的度量。选项包括“angular”、“euclidean”、“manhattan”、“hamming”、“dot”。默认值:“angular”。 |
| secure | 使用 https/TLS | 覆盖从接口或端口参数推断的值。默认值:false。 |
| index_param | 索引参数 | 索引参数。默认值:“'L2Distance',100”。 |
| index_query_params | 索引查询参数 | 其他索引查询参数。 |
| search_query | 搜索查询 | 用于相似性搜索的查询字符串。 |
| ingest_data | 摄取数据 | 要摄取到向量存储中的数据。 |
| embedding | 嵌入 | 要使用的嵌入模型。 |
| number_of_results | 结果数量 | 相似性搜索中返回的结果数量。默认值:4。 |
| score_threshold | 分数阈值 | 相似度分数阈值。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | Clickhouse 向量存储。 |
| search_results | 搜索结果 | 相似性搜索的结果,作为数据对象列表。 |
Couchbase
此组件创建具有搜索功能的 Couchbase 向量存储。有关更多信息,请参阅Couchbase 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| couchbase_connection_string | SecretString | Couchbase 集群连接字符串。必需。 |
| couchbase_username | 字符串 | Couchbase 用户名。必需。 |
| couchbase_password | SecretString | Couchbase 密码。必需。 |
| bucket_name | 字符串 | Couchbase 桶名称。必需。 |
| scope_name | 字符串 | Couchbase Scope 名称。必需。 |
| collection_name | 字符串 | Couchbase 集合名称。必需。 |
| index_name | 字符串 | Couchbase 索引名称。必需。 |
| search_query | 字符串 | 要在向量存储中搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据列表。 |
| embedding | 嵌入 | 用于向量存储的嵌入函数。 |
| number_of_results | 整数 | 搜索返回的结果数量。默认值:4。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | CouchbaseVectorStore | 配置了指定参数的 Couchbase 向量存储实例。 |
本地数据库
本地数据库组件是 Langflow 增强版的 Chroma DB。
该组件增加了友好的用户界面,包含两种模式(摄取和检索),支持自动集合管理,并在 Langflow 的缓存目录中内置了持久化功能。
本地数据库包含摄取和检索模式。
摄取模式类似于ChromaDB,并将您的数据库持久化到 Langflow 缓存目录中。Langflow 缓存目录的位置在LANGFLOW_CONFIG_DIR中指定。有关更多信息,请参阅环境变量。
检索模式可以查询您的 Chroma DB 集合。
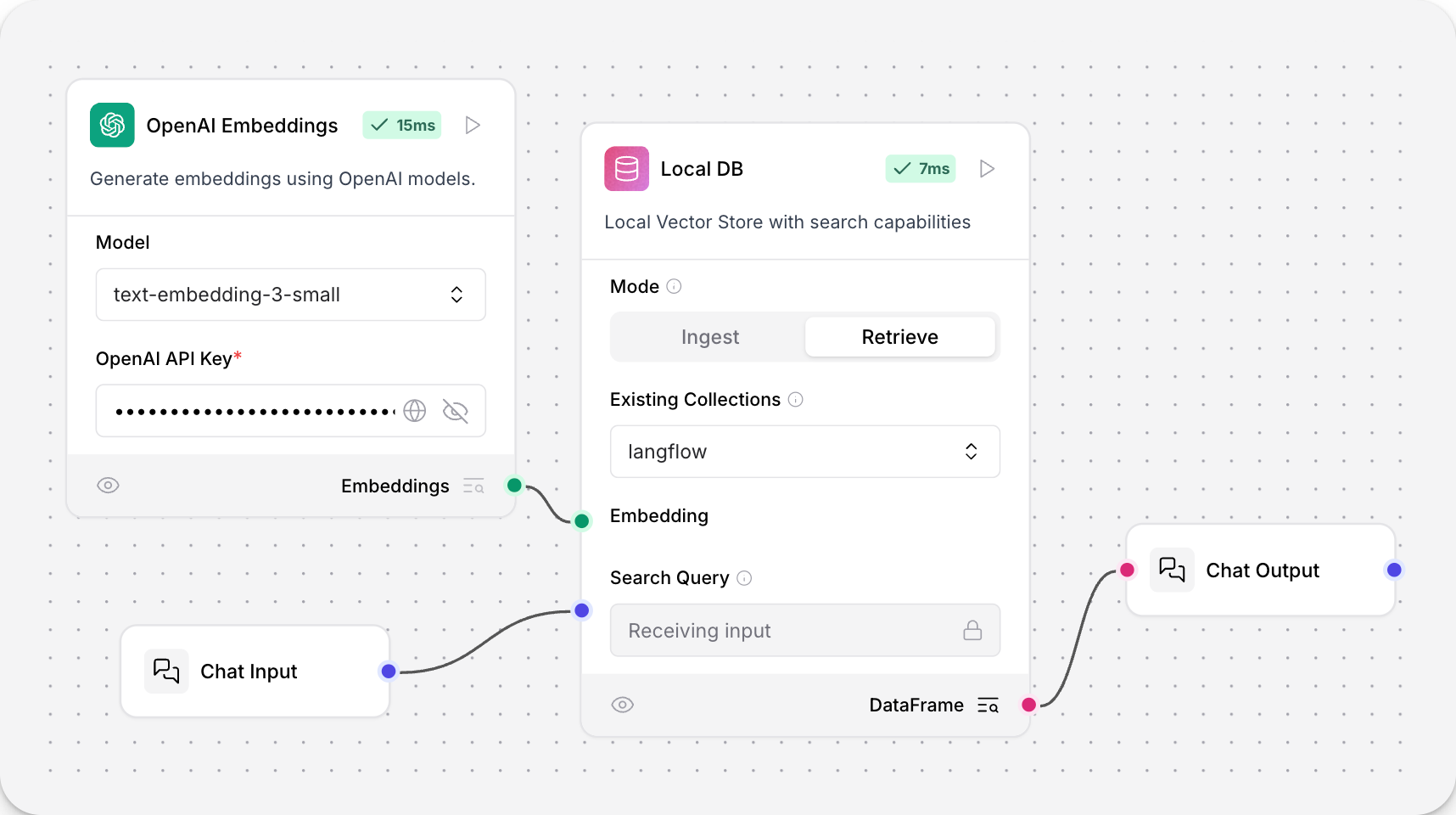
有关更多信息,请参阅Chroma 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| collection_name | 字符串 | Chroma 集合的名称。默认值:“langflow”。 |
| persist_directory | 字符串 | 保存向量存储的自定义基础目录。集合存储在{directory}/vector_stores/{collection_name}下。如果未指定,将使用您系统的缓存文件夹。 |
| existing_collections | 字符串 | 选择一个之前创建的集合来搜索其存储的数据。 |
| embedding | 嵌入 | 用于向量存储的嵌入函数。 |
| allow_duplicates | 布尔值 | 如果为 false,将不会添加向量存储中已有的文档。 |
| search_type | 字符串 | 要执行的搜索类型:“相似度”或“MMR”。 |
| ingest_data | 数据/DataFrame | 要存储的数据。它被嵌入并索引用于语义搜索。 |
| search_query | 字符串 | 输入文本以在选定的集合中搜索相似内容。 |
| number_of_results | 整数 | 返回的结果数量。默认值:10。 |
| limit | 整数 | 当允许重复为 False 时,要比较的记录数量限制。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Chroma | 配置了指定参数的本地 Chroma 向量存储实例。 |
| search_results | 列表数据 | 作为数据对象列表的相似性搜索结果。 |
Elasticsearch
此组件创建具有搜索功能的 Elasticsearch 向量存储。有关更多信息,请参阅Elasticsearch 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| es_url | 字符串 | Elasticsearch 服务器 URL。 |
| es_user | 字符串 | 用于 Elasticsearch 认证的用户名。 |
| es_password | SecretString | 用于 Elasticsearch 认证的密码。 |
| index_name | 字符串 | Elasticsearch 索引名称。 |
| strategy | 字符串 | 向量搜索策略。选项包括“近似 k 近邻”或“脚本评分”。 |
| distance_strategy | 字符串 | 距离计算策略。选项包括“余弦”、“欧氏距离”或“点积”。 |
| search_query | 字符串 | 用于相似性搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据。 |
| embedding | 嵌入 | 要使用的嵌入函数。 |
| number_of_results | 整数 | 搜索返回的结果数量。默认值:4。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | ElasticsearchStore | Elasticsearch 向量存储实例。 |
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |
FAISS
此组件创建具有搜索功能的 FAISS 向量存储。有关更多信息,请参阅FAISS 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| index_name | 字符串 | FAISS 索引名称。默认值:“langflow_index”。 |
| persist_directory | 字符串 | 保存 FAISS 索引的路径。它是相对于 Langflow 运行位置的相对路径。 |
| search_query | 字符串 | 要在向量存储中搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据列表。 |
| allow_dangerous_deserialization | 布尔值 | 设置为 True 以允许从不受信任的来源加载 pickle 文件。默认值:True。 |
| embedding | 嵌入 | 用于向量存储的嵌入函数。 |
| number_of_results | 整数 | 搜索返回的结果数量。默认值:4。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | 配置了指定参数的 FAISS 向量存储实例。 |
| search_results | 搜索结果 | 作为数据对象列表的相似性搜索结果。 |
Graph RAG
此组件在向量存储中执行 Graph RAG(检索增强生成)遍历,实现基于图的文档检索。有关更多信息,请参阅Graph RAG 文档。
有关示例流程,请参阅Graph RAG模板。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embedding_model | 嵌入模型 | 指定嵌入模型。对于使用Astra vectorize嵌入的集合,这不是必需的。 |
| vector_store | 向量存储连接 | 连接到向量存储。 |
| edge_definition | 边定义 | 图遍历的边定义。有关更多信息,请参阅GraphRAG 文档。 |
| strategy | 遍历策略 | 用于图遍历的策略。策略选项会从可用策略中动态加载。 |
| search_query | 搜索查询 | 要在向量存储中搜索的查询。 |
| graphrag_strategy_kwargs | 策略参数 | 检索策略的其他可选参数字典。有关更多信息,请参阅策略文档。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| search_results | 列表[数据] | 基于图的文档检索结果,作为数据对象列表。 |
超融合数据库 (HCD)
此组件使用 HCD 实现向量存储。
要使用 HCD 向量存储,请添加您的部署的集合名称、用户名、密码和 HCD Data API 端点。端点必须采用http[s]://**DOMAIN_NAME** 或 **IP_ADDRESS**[:port]格式,例如http://192.0.2.250:8181。
将DOMAIN_NAME或IP_ADDRESS替换为您 HCD Data API 连接的域名或 IP 地址。
要使用 HCD 向量存储进行嵌入摄取,请将其连接到嵌入模型和文件加载器
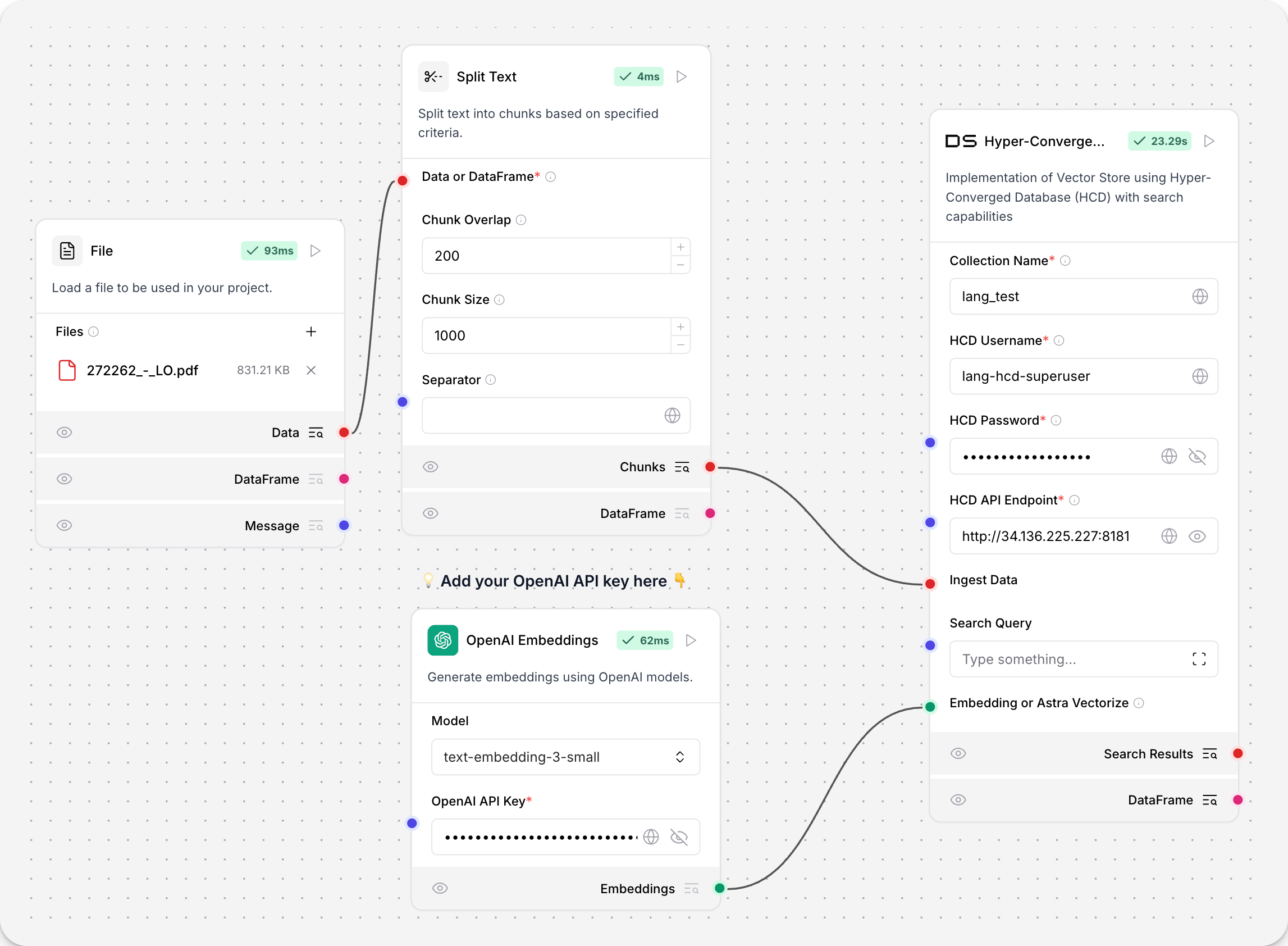
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| collection_name | 集合名称 | 向量将存储在 HCD 中的集合名称。必需。 |
| username | HCD 用户名 | 用于访问 HCD 的认证用户名。默认值为“hcd-superuser”。必需。 |
| password | HCD 密码 | 用于访问 HCD 的认证密码。必需。 |
| api_endpoint | HCD API 端点 | HCD 服务的 API 端点 URL。必需。 |
| search_input | 搜索输入 | 用于相似性搜索的查询字符串。 |
| ingest_data | 摄取数据 | 要摄取到向量存储中的数据。 |
| namespace | 命名空间 | HCD 中用于集合的可选命名空间。默认值为“default_namespace”。 |
| ca_certificate | CA 证书 | 用于与 HCD 建立 TLS 连接的可选 CA 证书。 |
| metric | 度量 | 向量比较的可选距离度量。选项包括“cosine”、“dot_product”、“euclidean”。 |
| batch_size | 批量大小 | 单个批次中处理的可选数据数量。 |
| bulk_insert_batch_concurrency | 批量插入批次并发 | 批量插入操作的可选并发级别。 |
| bulk_insert_overwrite_concurrency | 批量插入覆盖并发 | 覆盖现有数据的批量插入操作的可选并发级别。 |
| bulk_delete_concurrency | 批量删除并发 | 批量删除操作的可选并发级别。 |
| setup_mode | 设置模式 | 设置向量存储的配置模式。选项包括“同步”、“异步”、“关闭”。默认值为“同步”。 |
| pre_delete_collection | 预删除集合 | 用于确定在创建新集合之前是否删除现有集合的布尔标志。 |
| metadata_indexing_include | 元数据索引包含 | 索引中要包含的可选元数据字段列表。 |
| embedding | 嵌入或 Astra Vectorize | 允许使用嵌入模型或 Astra Vectorize 配置。 |
| metadata_indexing_exclude | 元数据索引排除 | 索引中要排除的可选元数据字段列表。 |
| collection_indexing_policy | 集合索引策略 | 定义集合索引策略的可选字典。 |
| number_of_results | 结果数量 | 相似性搜索中返回的结果数量。默认值为 4。 |
| search_type | 搜索类型 | 要使用的搜索类型。选项包括“相似度”、“带分数阈值的相似度”、“MMR(最大边际相关性)”。默认值为“相似度”。 |
| search_score_threshold | 搜索分数阈值 | 搜索结果的最低相似度分数阈值。默认值为 0。 |
| search_filter | 搜索元数据过滤器 | 应用于搜索查询的可选过滤器字典。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | HyperConvergedDatabaseVectorStore | HCD 向量存储实例。 |
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |
Milvus
此组件创建具有搜索功能的 Milvus 向量存储。有关更多信息,请参阅Milvus 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| collection_name | 字符串 | Milvus 集合名称。 |
| collection_description | 字符串 | Milvus 集合的描述。 |
| uri | 字符串 | Milvus 连接 URI。 |
| password | SecretString | Milvus 密码。 |
| username | SecretString | Milvus 用户名。 |
| batch_size | 整数 | 单个批次中处理的数据数量。 |
| search_query | 字符串 | 用于相似性搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据。 |
| embedding | 嵌入 | 要使用的嵌入函数。 |
| number_of_results | 整数 | 搜索中返回的结果数量。 |
| search_type | 字符串 | 要执行的搜索类型。 |
| search_score_threshold | 浮点数 | 搜索结果的最低相似度分数。 |
| search_filter | 字典 | 搜索查询的元数据过滤器。 |
| setup_mode | 字符串 | 设置向量存储的配置模式。 |
| vector_dimensions | 整数 | 向量的维度数量。 |
| pre_delete_collection | 布尔值 | 在创建新集合之前是否删除现有集合。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Milvus | 配置了指定参数的 Milvus 向量存储实例。 |
MongoDB Atlas
此组件创建具有搜索功能的 MongoDB Atlas 向量存储。有关更多信息,请参阅MongoDB Atlas 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| mongodb_atlas_cluster_uri | SecretString | 您的 MongoDB Atlas 集群的连接 URI。必需。 |
| enable_mtls | 布尔值 | 启用相互 TLS 认证。默认值:false。 |
| mongodb_atlas_client_cert | SecretString | 用于 mTLS 认证的客户端证书与私钥组合。如果启用 mTLS,则必需。 |
| db_name | 字符串 | 要使用的数据库名称。必需。 |
| collection_name | 字符串 | 要使用的集合名称。必需。 |
| index_name | 字符串 | Atlas Search 索引的名称,它应该是向量搜索类型。必需。 |
| insert_mode | 字符串 | 如何将新文档插入集合。选项包括“追加”或“覆盖”。默认值:“追加”。 |
| embedding | 嵌入 | 要使用的嵌入模型。 |
| number_of_results | 整数 | 相似性搜索中返回的结果数量。默认值:4。 |
| index_field | 字符串 | 要索引的字段。默认值:“embedding”。 |
| filter_field | 字符串 | 过滤索引的字段。 |
| number_dimensions | 整数 | 嵌入上下文长度。默认值:1536。 |
| similarity | 字符串 | 用于测量向量间相似度的方法。选项包括“余弦”、“欧氏距离”或“点积”。默认值:“余弦”。 |
| quantization | 字符串 | 量化通过将 32 位浮点数转换为更小的数据类型来降低内存成本。选项包括“标量”或“二进制”。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | MongoDBAtlasVectorSearch | MongoDB Atlas 向量存储实例。 |
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |
Opensearch
此组件创建具有搜索功能的 Opensearch 向量存储。有关更多信息,请参阅Opensearch 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| opensearch_url | 字符串 | OpenSearch 集群 URL,例如https://192.168.1.1:9200。 |
| index_name | 字符串 | OpenSearch 集群中存储向量的索引名称。 |
| search_input | 字符串 | 输入搜索查询。留空以检索所有文档或在使用混合搜索时留空。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据。 |
| embedding | 嵌入 | 要使用的嵌入函数。 |
| search_type | 字符串 | 选项包括“similarity”、“similarity_score_threshold”、“mmr”。 |
| number_of_results | 整数 | 搜索返回的结果数量。 |
| search_score_threshold | 浮点数 | 搜索结果的最低相似度分数阈值。 |
| username | 字符串 | 开源集群的用户名。 |
| password | SecretString | 开源集群的密码。 |
| use_ssl | 布尔值 | 使用 SSL。 |
| verify_certs | 布尔值 | 验证证书。 |
| hybrid_search_query | 字符串 | 以 JSON 格式提供自定义混合搜索查询。这允许您结合向量相似度和关键词匹配。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | OpenSearchVectorSearch | OpenSearch 向量存储实例 |
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |
PGVector
此组件创建具有搜索功能的 PGVector 向量存储。有关更多信息,请参阅PGVector 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| pg_server_url | SecretString | PostgreSQL 服务器连接字符串。 |
| collection_name | 字符串 | 向量存储的表名。 |
| search_query | 字符串 | 用于相似性搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据。 |
| embedding | 嵌入 | 要使用的嵌入函数。 |
| number_of_results | 整数 | 搜索返回的结果数量。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | 配置了指定参数的 PGVector 向量存储实例。 |
| search_results | 搜索结果 | 作为数据对象列表的相似性搜索结果。 |
Pinecone
此组件创建具有搜索功能的 Pinecone 向量存储。有关更多信息,请参阅Pinecone 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| index_name | 字符串 | Pinecone 索引名称。 |
| namespace | 字符串 | 索引的命名空间。 |
| distance_strategy | 字符串 | 计算向量间距离的策略。 |
| pinecone_api_key | SecretString | Pinecone 的 API 密钥。 |
| text_key | 字符串 | 记录中用作文本的键。 |
| search_query | 字符串 | 用于相似性搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据。 |
| embedding | 嵌入 | 要使用的嵌入函数。 |
| number_of_results | 整数 | 搜索返回的结果数量。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| vector_store | 向量存储 | 配置了指定参数的 Pinecone 向量存储实例。 |
| search_results | 搜索结果 | 作为数据对象列表的相似性搜索结果。 |
Qdrant
此组件创建具有搜索功能的 Qdrant 向量存储。有关更多信息,请参阅Qdrant 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| collection_name | 字符串 | Qdrant 集合名称。 |
| host | 字符串 | Qdrant 服务器主机。 |
| port | 整数 | Qdrant 服务器端口。 |
| grpc_port | 整数 | Qdrant gRPC 端口。 |
| api_key | SecretString | Qdrant 的 API 密钥。 |
| prefix | 字符串 | Qdrant 的前缀。 |
| timeout | 整数 | Qdrant 操作的超时时间。 |
| path | 字符串 | Qdrant 的路径。 |
| url | 字符串 | Qdrant 的 URL。 |
| distance_func | 字符串 | 用于向量相似度的距离函数。 |
| content_payload_key | 字符串 | 内容 payload 键。 |
| metadata_payload_key | 字符串 | 元数据 payload 键。 |
| search_query | 字符串 | 用于相似性搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据。 |
| embedding | 嵌入 | 要使用的嵌入函数。 |
| number_of_results | 整数 | 搜索返回的结果数量。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Qdrant | 一个 Qdrant 向量存储实例。 |
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |
Redis
此组件创建具有搜索功能的 Redis 向量存储。有关更多信息,请参阅Redis 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| redis_server_url | SecretString | Redis 服务器连接字符串。 |
| redis_index_name | 字符串 | Redis 索引名称。 |
| code | 字符串 | Redis 的自定义代码(高级)。 |
| schema | 字符串 | Redis 索引的架构。 |
| search_query | 字符串 | 用于相似性搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据。 |
| number_of_results | 整数 | 搜索返回的结果数量。 |
| embedding | 嵌入 | 要使用的嵌入函数。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | Redis | Redis 向量存储实例 |
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |
Supabase
此组件创建与 Supabase 向量存储的连接,并具有搜索功能。有关更多信息,请参阅Supabase 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| supabase_url | 字符串 | Supabase 实例的 URL。 |
| supabase_service_key | SecretString | 用于 Supabase 认证的服务密钥。 |
| table_name | 字符串 | Supabase 中的表名。 |
| query_name | 字符串 | 要使用的查询名称。 |
| search_query | 字符串 | 用于相似性搜索的查询。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据。 |
| embedding | 嵌入 | 要使用的嵌入函数。 |
| number_of_results | 整数 | 搜索返回的结果数量。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | SupabaseVectorStore | 一个 Supabase 向量存储实例。 |
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |
Upstash
此组件创建具有搜索功能的 Upstash 向量存储。有关更多信息,请参阅Upstash 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| index_url | 字符串 | Upstash 索引的 URL。 |
| index_token | SecretString | Upstash 索引的 token。 |
| text_key | 字符串 | 记录中用作文本的键。 |
| namespace | 字符串 | 索引的命名空间。 |
| search_query | 字符串 | 用于相似性搜索的查询。 |
| metadata_filter | 字符串 | 按元数据过滤文档。 |
| ingest_data | 数据 | 要摄取到向量存储中的数据。 |
| embedding | 嵌入 | 要使用的嵌入函数。 |
| number_of_results | 整数 | 搜索返回的结果数量。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | UpstashVectorStore | 一个 Upstash 向量存储实例。 |
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |
Vectara
此组件创建具有搜索功能的 Vectara 向量存储。有关更多信息,请参阅Vectara 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| vectara_customer_id | 字符串 | Vectara 客户 ID。 |
| vectara_corpus_id | 字符串 | Vectara 语料库 ID。 |
| vectara_api_key | SecretString | Vectara API 密钥。 |
| embedding | 嵌入 | 要使用的嵌入函数(可选)。 |
| ingest_data | 列表[文档/数据] | 要摄取到向量存储中的数据。 |
| search_query | 字符串 | 用于相似性搜索的查询。 |
| number_of_results | 整数 | 搜索返回的结果数量。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | VectaraVectorStore | Vectara 向量存储实例。 |
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |
Vectara 搜索
此组件根据提供的输入搜索 Vectara 向量存储中的文档。有关更多信息,请参阅Vectara 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| search_type | 字符串 | 搜索类型,例如“相似度”或“MMR”。 |
| input_value | 字符串 | 搜索查询。 |
| vectara_customer_id | 字符串 | Vectara 客户 ID。 |
| vectara_corpus_id | 字符串 | Vectara 语料库 ID。 |
| vectara_api_key | SecretString | Vectara API 密钥。 |
| files_url | 列表[字符串] | 文件初始化的可选 URL。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |
Weaviate
此组件方便设置 Weaviate 向量存储,优化文本和文档索引与检索。有关更多信息,请参阅Weaviate 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| weaviate_url | 字符串 | 默认实例 URL。 |
| search_by_text | 布尔值 | 指示是否按文本搜索。 |
| api_key | SecretString | 用于认证的可选 API 密钥。 |
| index_name | 字符串 | 可选的索引名称。 |
| text_key | 字符串 | 默认的文本提取键。 |
| input | 文档 | 文档或记录。 |
| embedding | 嵌入 | 使用的嵌入模型。 |
| attributes | 列表[字符串] | 可选的附加属性。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| vector_store | WeaviateVectorStore | Weaviate 向量存储实例。 |
Weaviate 搜索
此组件搜索 Weaviate 向量存储中与输入相似的文档。有关更多信息,请参阅Weaviate 文档。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| search_type | 字符串 | 搜索类型,例如“相似度”或“MMR” |
| input_value | 字符串 | 搜索查询。 |
| weaviate_url | 字符串 | 默认实例 URL。 |
| search_by_text | 布尔值 | 一个布尔值,指示是否按文本搜索。 |
| api_key | SecretString | 用于认证的可选 API 密钥。 |
| index_name | 字符串 | 可选的索引名称。 |
| text_key | 字符串 | 默认的文本提取键。 |
| embedding | 嵌入 | 使用的嵌入模型。 |
| attributes | 列表[字符串] | 可选的附加属性。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| search_results | 列表[数据] | 作为数据对象列表的相似性搜索结果。 |