处理
处理组件用于在流程中处理和转换数据。
在流程中使用处理组件
此流程中的分割文本处理组件将传入的数据分割成块,以便嵌入到向量存储组件中。
该组件提供了对块大小、重叠和分隔符的控制,这会影响向量存储检索结果的上下文和粒度。
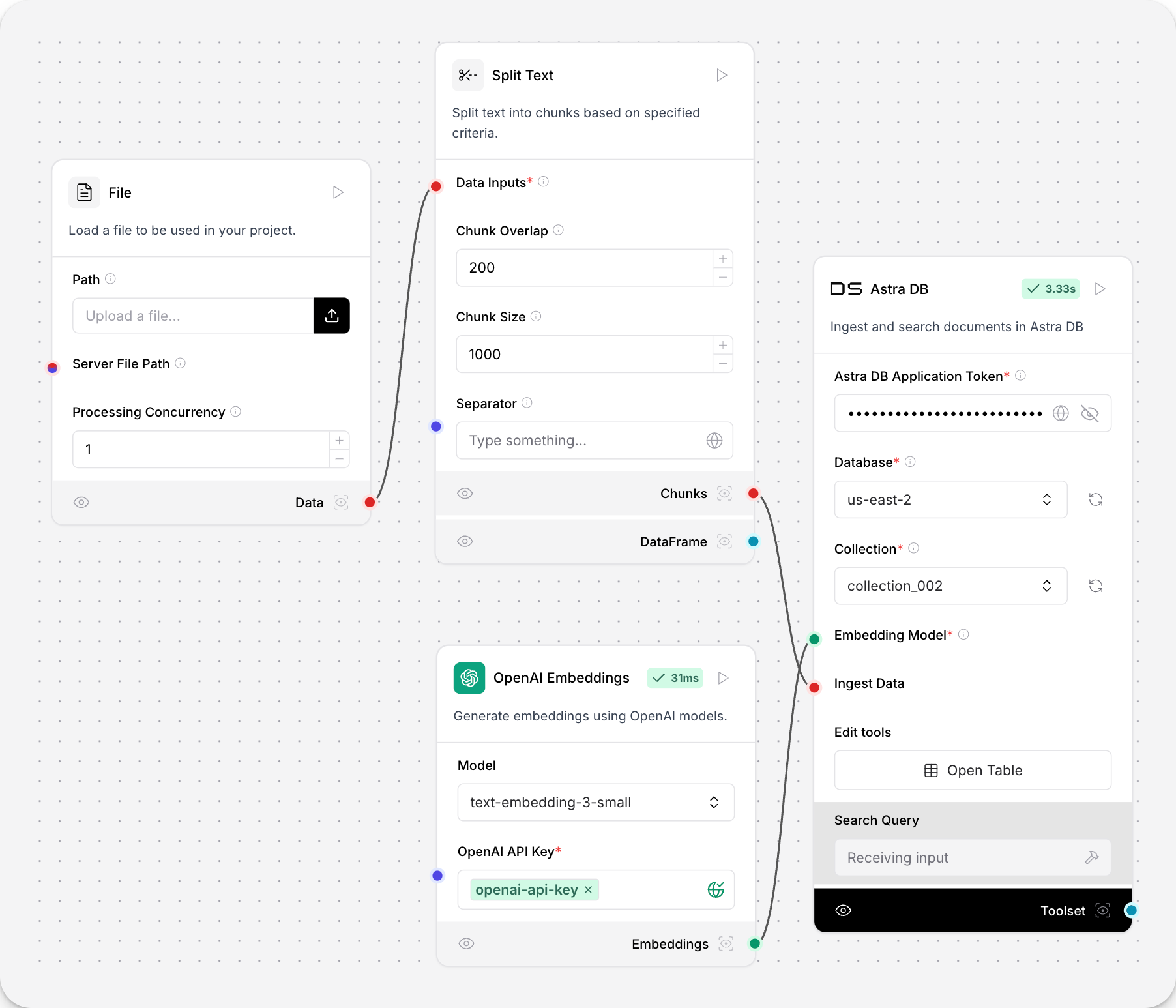
合并数据
在 Langflow 版本 1.1.3 之前,此组件名为合并数据。
此组件将多个数据源合并为一个统一的数据对象。
该组件迭代处理输入的数据对象列表,将它们合并成一个单一的数据对象。如果输入列表为空,则返回一个空的数据对象。如果只有一个输入数据对象,则原样返回该对象。合并过程使用加法运算符来组合数据对象。
参数
合并文本
此组件使用指定的分隔符将两个文本源连接成一个文本块。
- 要在流程中使用此组件,请将输出消息的两个组件连接到合并文本组件的第一个文本和第二个文本输入。此示例使用两个文本输入组件。
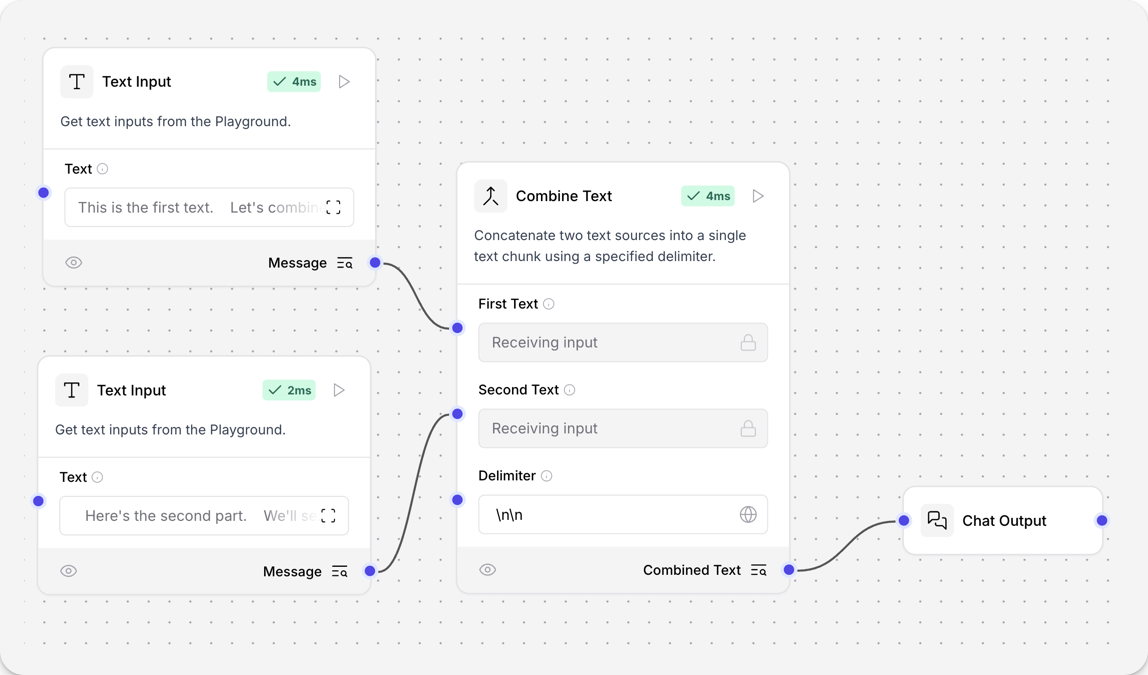
- 在合并文本组件中,在两个文本输入组件的文本字段中输入一些要合并的文本。
- 在合并文本组件中,输入一个可选的分隔符值。分隔符字符用于分隔组合的文本。此示例使用
\n\n **第一个文本结束** \n\n **第二个文本开始** \n\n来标记文本并在它们之间创建新行。 - 连接一个聊天输出组件来查看文本组合。
- 点击Playground,然后点击运行流程。组合后的文本将出现在Playground中。
_10这是第一个文本。让我们来合并文本!_10第一个文本结束_10第二个文本开始_10这是第二部分。我们将看看文本合并是如何工作的。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| first_text | 第一个文本 | 要连接的第一个文本输入。 |
| second_text | 第二个文本 | 要连接的第二个文本输入。 |
| delimiter | 分隔符 | 用于分隔两个文本输入的字符串。默认为空格。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| message | 消息 | 包含组合文本的消息对象。 |
DataFrame 操作
此组件对 DataFrame 的行和列执行操作。
要在流程中使用此组件,请将输出DataFrame的组件连接到DataFrame 操作组件。
此示例从 API 获取 JSON 数据。Lambda 过滤器组件提取结果并将其展平为表格形式的 DataFrame。然后,DataFrame 操作组件可以处理检索到的数据。
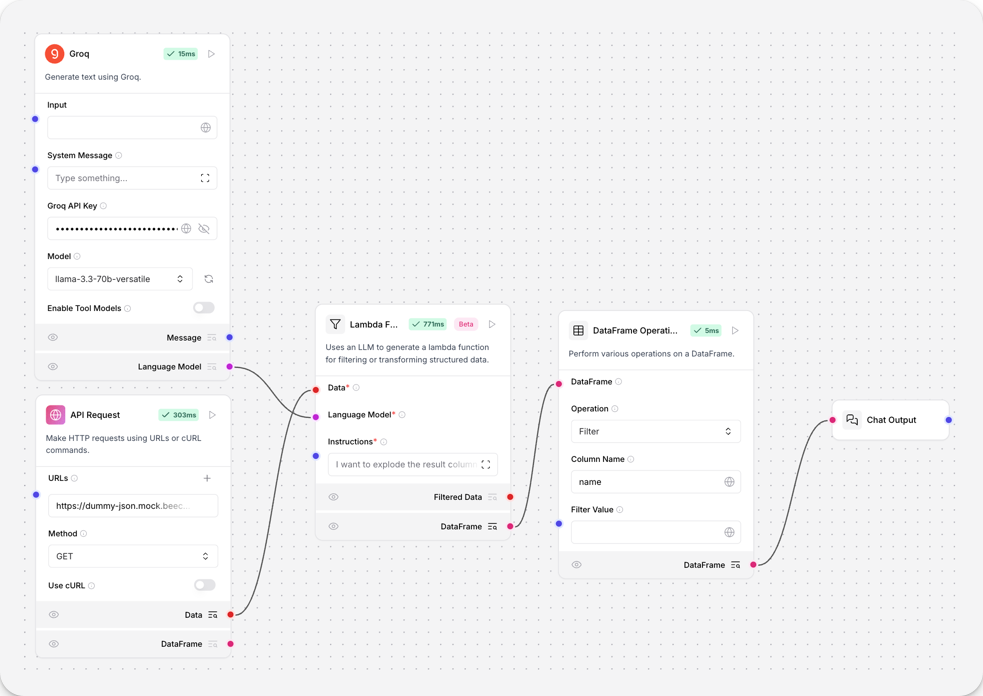
- API 请求组件仅检索包含
source和result字段的数据。对于此示例,所需数据嵌套在result字段内。 - 将一个Lambda 过滤器连接到 API 请求组件,并将一个语言模型连接到Lambda 过滤器。此示例连接了一个Groq模型组件。
- 在Groq模型组件中,添加您的 Groq API 密钥。
- 要过滤数据,在Lambda 过滤器组件的指令字段中,使用自然语言描述数据应如何过滤。对于此示例,输入
_10我想将结果列展开成一个数据对象
避免在指令字段中使用标点符号,因为它可能导致错误。
- 要运行流程,在Lambda 过滤器组件中,点击.
- 要检查过滤后的数据,在Lambda 过滤器组件中,点击。结果是一个结构化的 DataFrame。
_10id | name | company | username | email | address | zip_10---|------------------|----------------------|-----------------|------------------------------------|-------------------|-------_101 | Emily Johnson | ABC Corporation | emily_johnson | emily.johnson@abccorporation.com | 123 Main St | 12345_102 | Michael Williams | XYZ Corp | michael_williams| michael.williams@xyzcorp.com | 456 Elm Ave | 67890
- 将DataFrame 操作组件和一个聊天输出组件添加到流程中。
- 在DataFrame 操作组件的操作字段中,选择过滤。
- 要应用过滤器,在列名字段中输入要过滤的列。此示例按
name过滤。 - 点击Playground,然后点击运行流程。流程将从
name列中提取值。
_10name_10Emily Johnson_10Michael Williams_10John Smith_10...
操作
此组件可以对 Pandas DataFrame 执行以下操作。
| 操作 | 描述 | 所需输入 |
|---|---|---|
| 添加列 | 添加一个具有常量值的新列 | new_column_name, new_column_value |
| 删除列 | 移除指定的列 | column_name |
| 过滤 | 根据列值过滤行 | column_name, filter_value |
| Head | 返回前 n 行 | num_rows |
| 重命名列 | 重命名现有列 | column_name, new_column_name |
| 替换值 | 替换列中的值 | column_name, replace_value, replacement_value |
| 选择列 | 选择指定的列 | columns_to_select |
| 排序 | 按列对 DataFrame 进行排序 | column_name, ascending |
| Tail | 返回后 n 行 | num_rows |
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| df | DataFrame | 要操作的输入 DataFrame。 |
| operation | 操作 | 要执行的 DataFrame 操作。选项包括添加列、删除列、过滤、Head、重命名列、替换值、选择列、排序和 Tail。 |
| column_name | 列名 | 用于操作的列名。 |
| filter_value | 过滤值 | 用于过滤行的值。 |
| ascending | 升序排序 | 是否按升序排序。 |
| new_column_name | 新列名 | 重命名或添加列时的新列名。 |
| new_column_value | 新列值 | 用于填充新列的值。 |
| columns_to_select | 要选择的列 | 要选择的列名列表。 |
| num_rows | 行数 | 对于 Head/Tail 操作要返回的行数。默认为 5。 |
| replace_value | 要替换的值 | 要在列中替换的值。 |
| replacement_value | 替换为的值 | 用于替换的值。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| output | DataFrame | 操作后的结果 DataFrame。 |
数据转 DataFrame
此组件将一个或多个数据对象转换为DataFrame。每个数据对象对应结果 DataFrame 中的一行。.data属性中的字段成为列,.text字段(如果存在)放置在 'text' 列中。
- 要在流程中使用此组件,请将输出数据的组件连接到数据转 Dataframe 组件的输入。此示例连接一个Webhook组件,将
text和data转换为 DataFrame。 - 要查看流程的输出,请将一个聊天输出组件连接到数据转 Dataframe 组件。
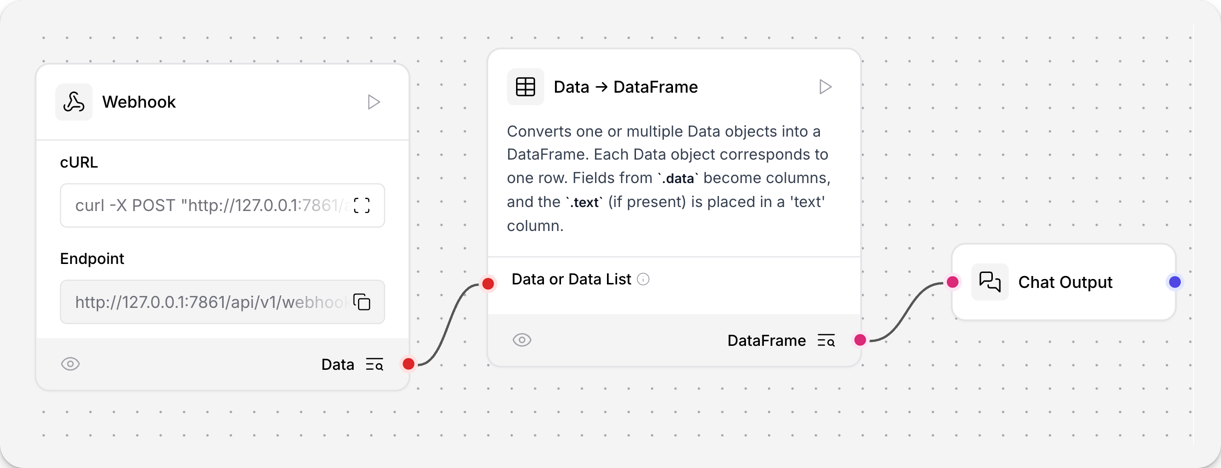
- 向包含您的 JSON 数据的Webhook发送 POST 请求。将
YOUR_FLOW_ID替换为您的流程 ID。此示例使用默认的 Langflow 服务器地址。
_10curl -X POST "http://127.0.0.1:7860/api/v1/webhook/YOUR_FLOW_ID" \_10-H 'Content-Type: application/json' \_10-d '{_10"text": "Alex Cruz - Employee Profile",_10"data": {_10"Name": "Alex Cruz",_10"Role": "Developer",_10"Department": "Engineering"_10 }_10}'
- 在Playground中,查看流程的输出。数据转 DataFrame 组件将 webhook 请求转换为一个
DataFrame,其中text和data字段作为列。
_10| text | data |_10|:-----------------------------|:------------------------------------------------------------------------|_10| Alex Cruz - Employee Profile | {'Name': 'Alex Cruz', 'Role': 'Developer', 'Department': 'Engineering'} |
- 发送另一个员工数据对象。
_10curl -X POST "http://127.0.0.1:7860/api/v1/webhook/YOUR_FLOW_ID" \_10-H 'Content-Type: application/json' \_10-d '{_10"text": "Kalani Smith - Employee Profile",_10"data": {_10"Name": "Kalani Smith",_10"Role": "Designer",_10"Department": "Design"_10 }_10}'
- 在Playground中,此请求也被转换为
DataFrame。
_10| text | data |_10|:--------------------------------|:---------------------------------------------------------------------|_10| Kalani Smith - Employee Profile | {'Name': 'Kalani Smith', 'Role': 'Designer', 'Department': 'Design'} |
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data_list | 数据或数据列表 | 要转换为 DataFrame 的一个或多个数据对象。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| dataframe | DataFrame | 从每个数据对象的字段以及一个文本列构建的 DataFrame。 |
过滤数据
此组件在 Langflow 版本 1.1.3 中处于 Beta 阶段,尚未完全支持。
此组件根据键列表过滤数据对象。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data | 数据 | 要过滤的数据对象。 |
| filter_criteria | 过滤条件 | 用于过滤的键列表。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| filtered_data | 过滤后的数据 | 一个只包含匹配过滤条件的键值对的新数据对象。 |
过滤值
此组件在 Langflow 版本 1.1.3 中处于 Beta 阶段,尚未完全支持。
过滤值组件根据指定的键、过滤值和比较运算符过滤数据项列表。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| input_data | 输入数据 | 要过滤的数据项列表。 |
| filter_key | 过滤键 | 用于过滤的键。 |
| filter_value | 过滤值 | 用于过滤的值。 |
| operator | 比较运算符 | 用于比较值的运算符。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| filtered_data | 过滤后的数据 | 过滤后的数据项列表。 |
Lambda 过滤器
此组件使用 LLM 生成 Lambda 函数,用于过滤或转换结构化数据。
要使用Lambda 过滤器组件,必须将其连接到语言模型组件,该组件用于根据指令字段中的自然语言指令生成函数。
此示例从https://jsonplaceholder.typicode.com/users API 端点获取 JSON 数据。Lambda 过滤器组件中的指令字段指定任务extract emails。连接的 LLM 根据指令创建一个过滤器,并成功从 JSON 数据中提取电子邮件地址列表。

参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data | 数据 | 用于使用 Lambda 函数过滤或转换的结构化数据。 |
| llm | 语言模型 | 与模型组件的连接端口。 |
| filter_instruction | 指令 | 关于如何使用 Lambda 函数过滤或转换数据的自然语言指令,例如仅包含状态为 'active' 的数据项。 |
| sample_size | 样本大小 | 对于大型数据集,从数据集头部和尾部采样的字符数。 |
| max_size | 最大大小 | 数据被视为“大型”时的字符数,达到此数量将触发按sample_size值进行采样。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| filtered_data | 过滤后的数据 | 过滤或转换后的数据对象。 |
| dataframe | DataFrame | 作为DataFrame的过滤后的数据。 |
LLM 路由器
此组件根据 OpenRouter 模型规范将请求路由到最合适的 LLM。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| models | 语言模型 | 要路由到的 LLM 列表。 |
| input_value | 输入 | 要路由的输入消息。 |
| judge_llm | 判断 LLM | 评估并选择最合适模型的 LLM。 |
| optimization | 优化 | 在质量、速度、成本或平衡之间的优化偏好。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| output | 输出 | 选定模型的响应。 |
| selected_model | 选定的模型 | 选定模型的名称。 |
消息转数据
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| message | 消息 | 要转换为数据对象的消息对象。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data | 数据 | 转换后的数据对象。 |
解析器
此组件使用模板将DataFrame或Data对象格式化为文本,并可以选择使用stringify直接将输入转换为字符串。
要使用此组件,请在template中创建变量,方式与在提示词组件中相同。对于DataFrames,使用列名,例如Name: {Name}。对于Data对象,使用{text}。
要将解析器组件与结构化输出组件一起使用,请执行以下操作
- 将结构化输出组件的DataFrame输出连接到解析器组件的DataFrame输入。
- 将文件组件连接到结构化输出组件的消息输入。
- 将OpenAI模型组件的语言模型输出连接到结构化输出组件的语言模型输入。
流程如下所示

- 在结构化输出组件中,点击打开表格。这将打开一个用于构建表格的窗格。表格包含名称、描述、类型和多个行。
- 创建一个映射到您从文件加载器加载的数据的表格。例如,要创建一个员工表格,您可能有
id、name和email行,它们都属于string类型。 - 在解析器组件的模板字段中,输入一个模板,用于将结构化输出组件的 DataFrame 输出解析为结构化文本。在
template中创建变量的方式与在提示词组件中相同。例如,以 Markdown 格式呈现员工表格
_10# 员工档案_10## 个人信息_10- **姓名:** {name}_10- **ID:** {id}_10- **电子邮件:** {email}
- 要运行流程,在解析器组件中,点击.
- 要查看解析后的文本,在解析器组件中,点击.
- (可选)连接一个聊天输出组件,并打开Playground查看输出。
有关使用解析器组件格式化来自结构化输出组件的 DataFrame 的更多示例,请参阅市场研究模板流程。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| mode | 模式 | “解析器”和“字符串化”模式之间的选项卡选择。“字符串化”将输入转换为字符串,而不是使用模板。 |
| pattern | 模板 | 使用大括号中的变量进行格式化的模板。对于 DataFrames,使用列名,例如Name: {Name}。对于 Data 对象,使用{text}。 |
| input_data | 数据或 DataFrame | 要解析的输入。接受 DataFrame 或 Data 对象。 |
| sep | 分隔符 | 用于分隔行或项的字符串。默认为换行符。 |
| clean_data | 清理数据 | 启用字符串化时,此选项通过删除空行和空白行来清理数据。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| parsed_text | 解析后的文本 | 结果格式化文本作为消息对象。 |
正则表达式提取器
此组件使用正则表达式从文本中提取模式。可用于从文本数据中查找和提取特定模式或信息。
要在流程中使用此组件
- 将正则表达式提取器连接到URL组件和聊天输出组件。
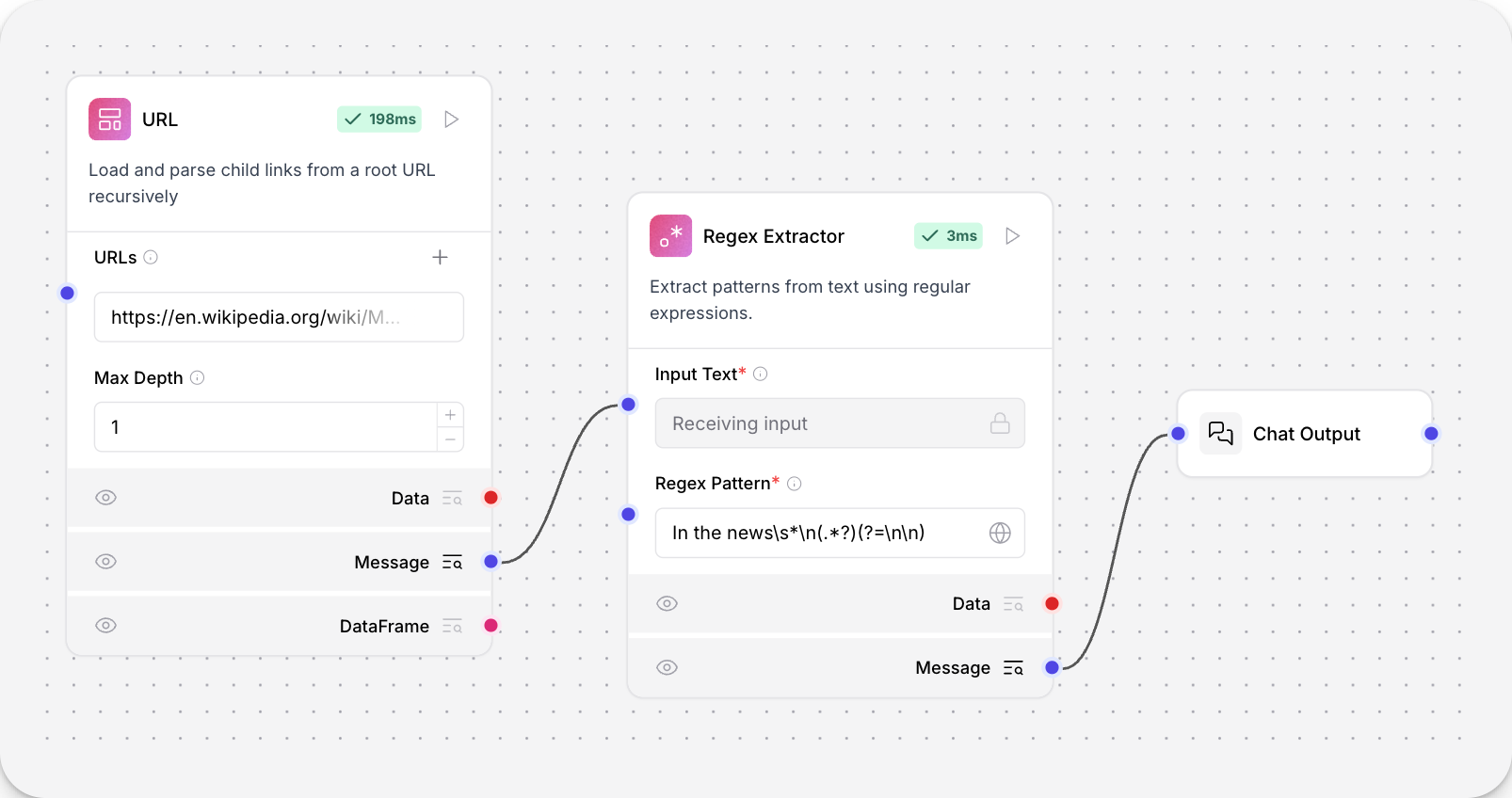
- 在正则表达式提取器工具中,输入一个模式以从URL组件的原始输出中提取文本。此示例从
https://en.wikipedia.org/wiki/Main_Page的“新闻报道”部分提取第一个段落
_10In the news\s*\n(.*?)(?=\n\n)
结果
_10秘鲁作家、诺贝尔文学奖得主马里奥·巴尔加斯·略萨(图)去世,享年 89 岁。
保存到文件
此组件将DataFrames、数据或消息保存为各种文件格式。
- 要在流程中使用此组件,请将输出DataFrames、数据或消息的组件连接到保存到文件组件的输入。以下示例将一个Webhook组件连接到两个保存到文件组件,以展示不同的输出。
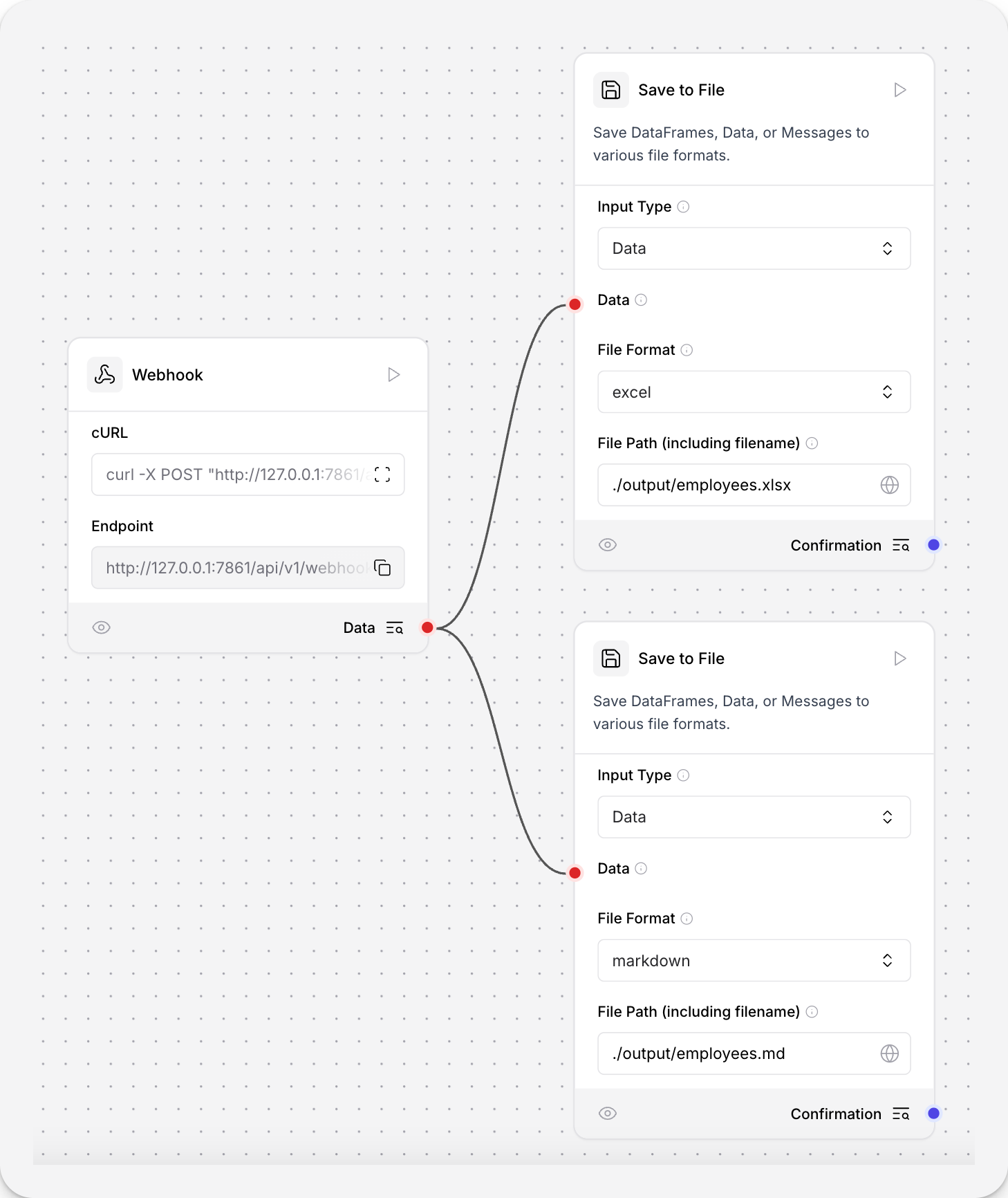
- 在保存到文件组件的输入类型字段中,选择预期的输入类型。此示例预期来自Webhook的数据。
- 在文件格式字段中,选择要保存文件的文件类型。此示例在一个保存到文件组件中使用
.md,在另一个中使用.xlsx。 - 在文件路径字段中,输入要保存文件的路径。此示例使用
./output/employees.xlsx和./output/employees.md将文件保存在相对于 Langflow 运行位置的目录中。该组件接受相对路径和绝对路径,并在需要时创建不存在的目录。
如果您在file_path中输入的格式不受支持,组件会将正确的格式附加到文件。例如,如果选定的file_format是csv,并且您输入的file_path是./output/test.txt,则文件将保存为./output/test.txt.csv,以免文件损坏。
- 向包含您的 JSON 数据的Webhook发送 POST 请求。将
YOUR_FLOW_ID替换为您的流程 ID。此示例使用默认的 Langflow 服务器地址。
_10curl -X POST "http://127.0.0.1:7860/api/v1/webhook/YOUR_FLOW_ID" \_10-H 'Content-Type: application/json' \_10-d '{_10"Name": ["Alex Cruz", "Kalani Smith", "Noam Johnson"],_10"Role": ["Developer", "Designer", "Manager"],_10"Department": ["Engineering", "Design", "Management"]_10}'
- 在您的本地文件系统中,打开
outputs目录。您应该会看到根据您发送的数据创建的两个文件:一个.xlsx文件用于结构化电子表格,一个 Markdown 文件。
_10| Name | Role | Department |_10|:-------------|:----------|:-------------|_10| Alex Cruz | Developer | Engineering |_10| Kalani Smith | Designer | Design |_10| Noam Johnson | Manager | Management |
文件输入格式选项
对于DataFrame和Data输入,组件可以创建
csvexceljsonmarkdownpdf
对于消息输入,组件可以创建
txtjsonmarkdownpdf
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| input_text | 输入文本 | 要分析和提取模式的文本。 |
| pattern | 正则表达式模式 | 要在文本中匹配的正则表达式模式。 |
| input_type | 输入类型 | 要保存的输入类型。 |
| df | DataFrame | 要保存的 DataFrame。 |
| data | 数据 | 要保存的数据对象。 |
| message | 消息 | 要保存的消息。 |
| file_format | 文件格式 | 用于保存输入的文件格式。 |
| file_path | 文件路径 | 完整的文件路径,包括文件名和扩展名。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data | 数据 | 提取的匹配项列表,作为数据对象。 |
| text | 消息 | 格式化为消息对象的提取匹配项。 |
| confirmation | 确认 | 保存文件后的确认消息。 |
分割文本
此组件根据指定条件将文本分割成块。非常适合将数据分块以进行分词和嵌入到向量数据库中。
分割文本组件输出块或DataFrame。块输出返回单个文本块的列表。DataFrame输出返回结构化数据格式,并应用额外的text和metadata列。
- 要在流程中使用此组件,请将输出数据或 DataFrame的组件连接到分割文本组件的数据端口。此示例使用URL组件,该组件正在获取 JSON 占位符数据。

- 在分割文本组件中,定义您的数据分割参数。
此示例使用分隔符},分割传入的 JSON 数据,因此每个块包含一个 JSON 对象。
优先级顺序是分隔符,然后是块大小,最后是块重叠。如果在按分隔符分割后任何段落长于chunk_size,它将再次分割以适应chunk_size。
在考虑chunk_size后,将在块之间应用块重叠以保持上下文。
- 将一个聊天输出组件连接到分割文本组件的DataFrame输出,以查看其输出。
- 点击Playground,然后点击运行流程。输出包含一个按
},分割的 JSON 对象表格。
_16{_16"userId": 1,_16"id": 1,_16"title": "Introduction to Artificial Intelligence",_16"body": "Learn the basics of Artificial Intelligence and its applications in various industries.",_16"link": "https://example.com/article1",_16"comment_count": 8_16},_16{_16"userId": 2,_16"id": 2,_16"title": "Web Development with React",_16"body": "Build modern web applications using React.js and explore its powerful features.",_16"link": "https://example.com/article2",_16"comment_count": 12_16},
- 清除分隔符字段,然后再次运行流程。输出将不再是 JSON 对象,而是包含 50 个字符的文本行,行之间有 10 个字符的重叠。
_10第一个块:“title”: “Introduction to Artificial Intelligence””_10第二个块:“elligence”, “body”: “Learn the basics of Artif”"_10第三个块:“s of Artificial Intelligence and its applications”"
参数
更新数据
此组件动态更新或附加带有指定字段的数据。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| old_data | 数据 | 要更新的记录。 |
| number_of_fields | 字段数 | 要添加的字段数。最大值为 15。 |
| text_key | 文本键 | 文本内容的键。 |
| text_key_validator | 文本键验证器 | 验证文本键是否存在。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data | 数据 | 更新后的数据对象。 |
旧版组件
旧版组件仍可使用,但不再受支持。
修改元数据
此组件修改输入对象的元数据。它可以添加新元数据、更新现有元数据以及删除指定的元数据字段。该组件可用于消息和数据对象,也可以从用户提供的文本创建新的数据对象。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| input_value | 输入 | 应添加元数据的对象 |
| text_in | 用户文本 | 文本输入;值包含在数据对象的 'text' 属性中。空文本条目将被忽略。 |
| metadata | 元数据 | 要添加到每个对象的元数据 |
| remove_fields | 要删除的字段 | 要删除的元数据字段 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data | 数据 | 输入对象列表,每个对象都添加了元数据 |
创建数据
此组件属于旧版,意味着自 Langflow 版本 1.1.3 起不再积极开发。
此组件动态创建一个具有指定字段数的数据对象。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| number_of_fields | 字段数 | 要添加到记录的字段数。 |
| text_key | 文本键 | 标识用作文本内容的字段的键。 |
| text_key_validator | 文本键验证器 | 如果启用,检查给定的文本键是否存在于给定的数据中。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| data | 数据 | 使用指定字段和文本键创建的数据对象。 |
JSON 清理器
JSON 清理器组件清理 JSON 字符串,以确保它们完全符合 JSON 规范。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| json_str | JSON 字符串 | 要清理的 JSON 字符串。这可以是原始的、可能格式不正确的 JSON 字符串,由语言模型或其他可能不完全符合 JSON 规范的来源生成。 |
| remove_control_chars | 移除控制字符 | 如果设置为 True,此选项将从 JSON 字符串中移除控制字符(ASCII 字符 0-31 和 127)。这有助于消除可能导致解析问题或使 JSON 无效的不可见字符。 |
| normalize_unicode | 规范化 Unicode | 启用后,此选项会将 JSON 字符串中的 Unicode 字符规范化为其规范组合形式 (NFC)。这确保了 Unicode 字符在不同系统中的一致表示,并防止了字符编码的潜在问题。 |
| validate_json | 验证 JSON | 如果设置为 True,此选项会在应用最终修复操作之前尝试解析 JSON 字符串,以确保其格式正确。如果 JSON 无效,它将引发 ValueError,从而可以早期检测 JSON 中的主要结构问题。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| output | 清理后的 JSON 字符串 | 结果是已清理、修复并验证过的 JSON 字符串,完全符合 JSON 规范。 |
解析 DataFrame
此组件在 Langflow 版本 1.3 后处于旧版,意味着不再积极开发。请改用解析器组件。
此组件使用模板将 DataFrames 转换为纯文本。
参数
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| df | DataFrame | 要转换为文本行的 DataFrame。 |
| template | 模板 | 格式化模板(使用{column_name}占位符)。 |
| sep | 分隔符 | 用于连接输出中各行的字符串。 |
输出
| 名称 | 显示名称 | 信息 |
|---|---|---|
| text | 文本 | 所有行合并为单个文本。 |
解析 JSON
此组件属于旧版,意味着自 Langflow 版本 1.1.3 起不再积极开发。
此组件使用 JQ 查询转换和提取 JSON 字段。
参数
选择数据
此组件属于旧版,意味着自 Langflow 版本 1.1.3 起不再积极开发。
此组件从列表中选择一个数据项。