Langflow 中的助手组件
助手组件提供实用功能,帮助您管理流程中的数据、任务和其他组件。
在流程中使用助手组件
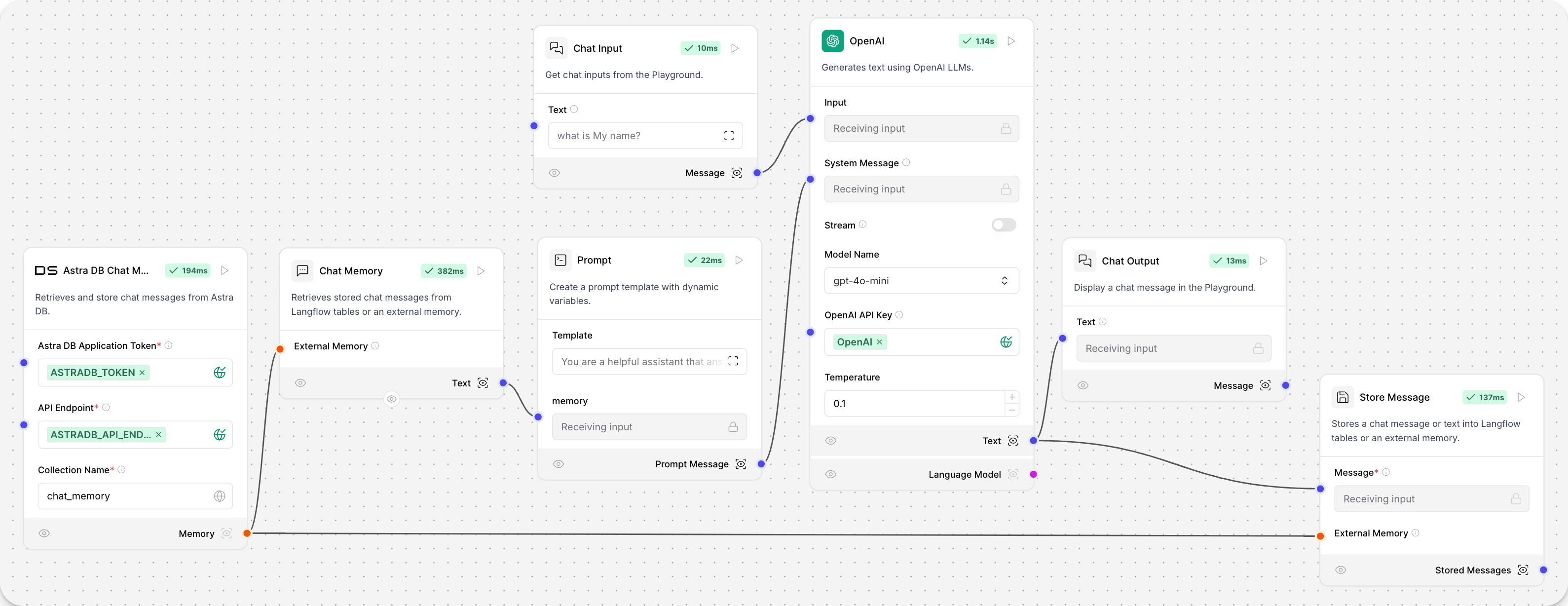
Langflow 中的聊天记忆可以存储在带有 LCBufferMemory 的本地 Langflow 表中,或者连接到外部数据库。
Store Message 助手组件将聊天记忆存储为 数据 对象,而 Message History 助手组件将聊天消息检索为数据对象或字符串。
此示例流程使用 Store Message 和 Chat Memory 组件从 AstraDBChatMemory 组件存储和检索聊天记录。
批量运行
批量运行组件对 DataFrame 文本列的每一行运行语言模型,并返回一个新的 DataFrame,其中包含原始文本和 LLM 响应。
响应包含以下列
text_input:输入 DataFrame 中的原始文本。model_response:模型对每个输入的响应。batch_index:处理顺序,基于0的索引。metadata(可选):有关处理的附加信息。
这些列连接到 Parser 组件时,可以在大括号内用作变量。
要将批量运行组件与 Parser 组件一起使用,请执行以下操作
- 将 Model 组件连接到 批量运行 组件的 Language model 端口。
- 将输出 DataFrame 的组件(如 File 组件)连接到 批量运行 组件的 DataFrame 输入。
- 将 批量运行 组件的 Batch Results 输出连接到 Parser 组件的 DataFrame 输入。流程如下图所示
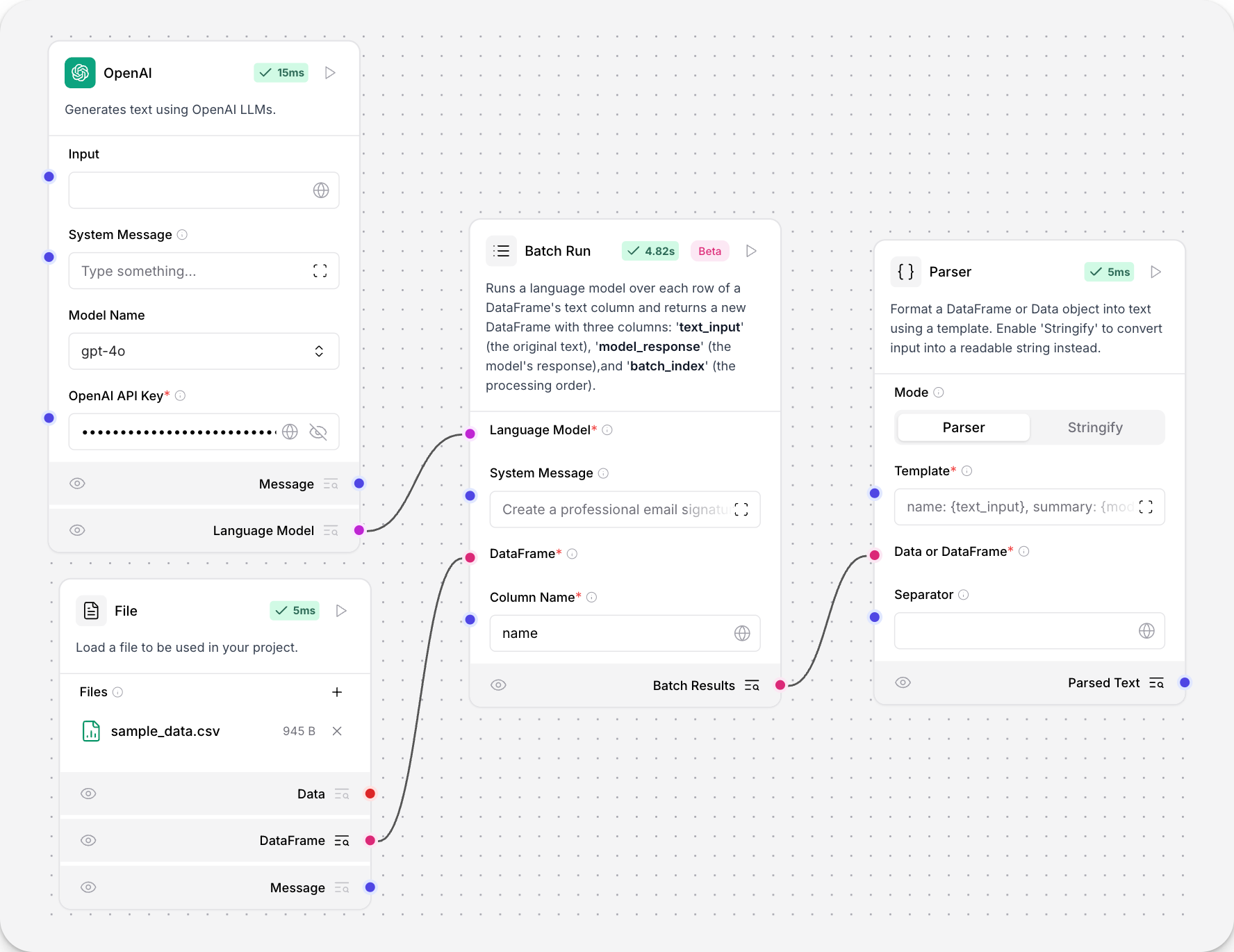
- 在 批量运行 组件的 Column Name 字段中,输入基于您从 File 加载器加载的数据的列名。例如,要处理
name列,输入name。 - 可选地,在 批量运行 组件的 System Message 字段中,输入一个 System Message 来指示连接的 LLM 如何处理您的文件。例如,
为每个名字创建一个名片。 - 在 Parser 组件的 Template 字段中,输入一个模板来使用 批量运行 组件的新 DataFrame 列。要使用 批量运行 组件的所有三列,请按如下方式包含它们
_10record_number: {batch_index}, name: {text_input}, summary: {model_response}
- 要运行流程,在 Parser 组件中,点击.
- 要查看您创建的 DataFrame,在 Parser 组件中,点击.
- 可选地,连接一个 Chat Output 组件,并打开 Playground 查看输出。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| model | HandleInput | 将 LLM 组件的“语言模型”输出连接到此处。必需。 |
| system_message | MultilineInput | DataFrame 中所有行的多行系统指令。 |
| df | DataFrameInput | 其列被视为文本消息的 DataFrame,由“column_name”指定。必需。 |
| column_name | MessageTextInput | 要视为文本消息的 DataFrame 列的名称。默认值='text'。必需。 |
| enable_metadata | BoolInput | 如果为 True,则将元数据添加到输出 DataFrame。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| batch_results | DataFrame | 一个包含以下列的 DataFrame:“text_input”、“model_response”、“batch_index”和可选的包含处理信息的“metadata”。 |
当前日期
当前日期组件返回选定时区的当前日期和时间。此组件提供了一种灵活的方式,可在 Langflow 流水线中获取特定时区的日期和时间信息。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| timezone | String | 当前日期和时间的时区。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| current_date | String | 选定时区的当前日期和时间结果。 |
ID 生成器
此组件生成唯一的 ID。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| unique_id | String | 生成的唯一 ID。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| id | String | 生成的唯一 ID。 |
消息历史
在 Langflow 1.1 之前,此组件被称为聊天记忆组件。
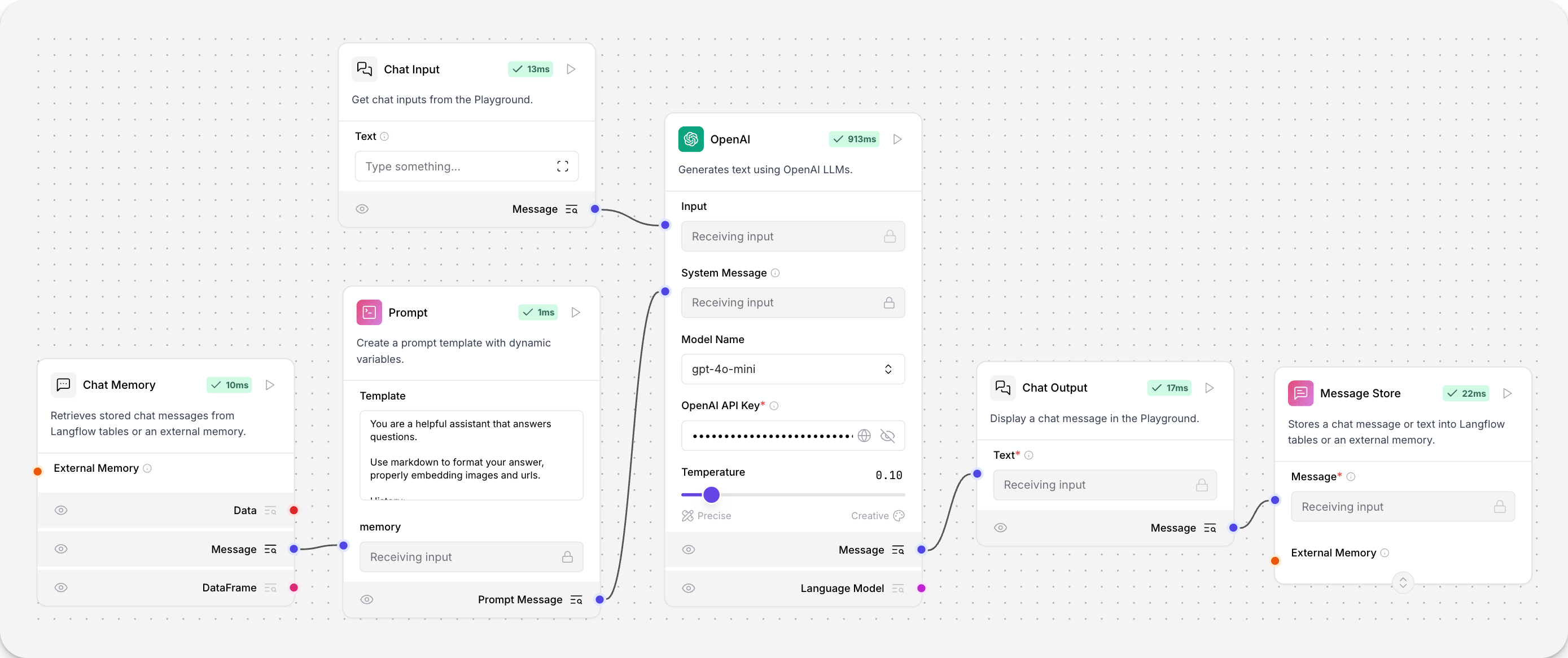
此组件从 Langflow 表或外部记忆中检索聊天消息。
在此示例中,Message Store 组件将完整的聊天记录存储在本地 Langflow 表中,Message History 组件将其检索为 LLM 回答每个问题的上下文。
有关在 Langflow 中配置记忆的更多信息,请参阅 记忆。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| memory | Memory | 从外部记忆中检索消息。如果为空,则使用 Langflow 表。 |
| sender | String | 按发送者类型过滤。 |
| sender_name | String | 按发送者名称过滤。 |
| n_messages | Integer | 要检索的消息数量。 |
| session_id | String | 聊天的会话 ID。如果为空,则使用当前会话 ID 参数。 |
| order | String | 消息的顺序。 |
| template | String | 用于格式化数据的模板。它可以包含键 {text}、{sender} 或消息数据中的任何其他键。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| messages | 数据 | 检索到的消息作为数据对象。 |
| messages_text | String | 格式化为文本的检索到的消息。 |
| lc_memory | Memory | 构建的 Langchain ConversationBufferMemory 对象。 |
消息存储
此组件将聊天消息或文本存储在 Langflow 表或外部记忆中。
在此示例中,Message Store 组件将完整的聊天记录存储在本地 Langflow 表中,Message History 组件将其检索为 LLM 回答每个问题的上下文。
有关在 Langflow 中配置记忆的更多信息,请参阅 记忆。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| message | String | 要存储的聊天消息。(必需) |
| memory | Memory | 存储消息的外部记忆。如果为空,则使用 Langflow 表。 |
| sender | String | 消息的发送者。可以是 Machine 或 User。如果为空,则使用当前发送者参数。 |
| sender_name | String | 发送者的名称。可以是 AI 或 User。如果为空,则使用当前发送者参数。 |
| session_id | String | 聊天的会话 ID。如果为空,则使用当前会话 ID 参数。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| stored_messages | List[Data] | 添加当前消息后存储的消息列表。 |
结构化输出
此组件将 LLM 响应转换为结构化数据格式。
在来自 Financial Support Parser 模板的示例中,结构化输出组件将非结构化财务报告转换为结构化数据。
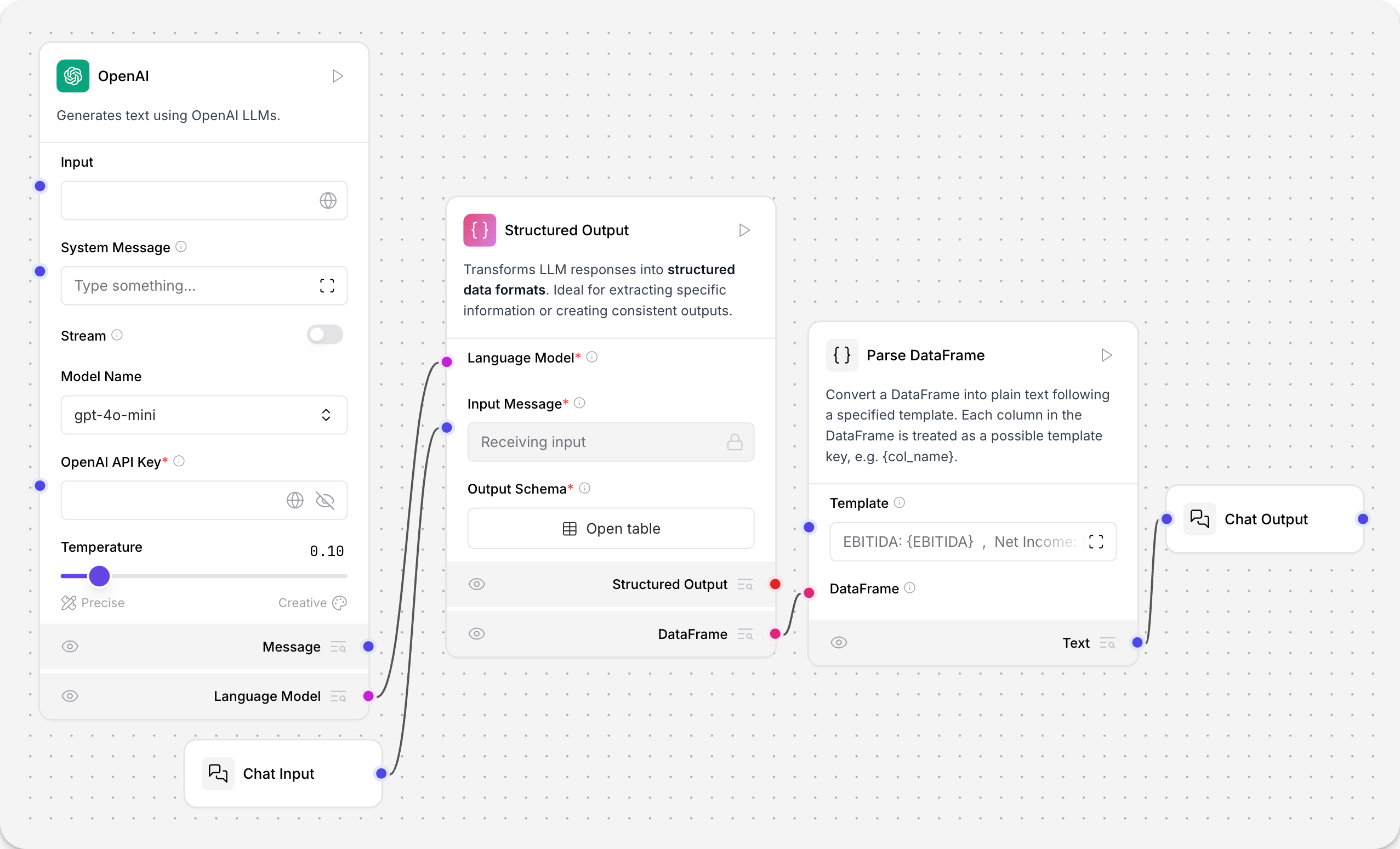
连接的 LLM 模型由 结构化输出 组件的 Format Instructions 参数提示,用于从非结构化文本中提取结构化输出。Format Instructions 用作 结构化输出 组件的系统提示。
在 结构化输出 组件中,单击 Open table 按钮以查看 Output Schema 表。Output Schema 参数使用包含以下字段的表定义模型输出的结构和数据类型
- 名称:输出字段的名称。
- 描述:输出字段的用途。
- 类型:输出字段的数据类型。可用类型包括
str、int、float、bool、list或dict。默认值为text。 - 多个:此功能已弃用。目前,如果您期望单个字段有多个值,则默认设置为
True。例如,features的list设置为True以包含多个值,例如["waterproof", "durable", "lightweight"]。默认值:True。
Parse DataFrame 组件将结构化输出解析为模板,以便在聊天输出中有序地呈现。模板接收来自 output_schema 表的值,并使用大括号。
例如,模板 EBITDA: {EBITDA} , Net Income: {NET_INCOME} , GROSS_PROFIT: {GROSS_PROFIT} 在 Playground 中呈现提取的值为 EBITDA: 900 million , Net Income: 500 million , GROSS_PROFIT: 1.2 billion。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| llm | LanguageModel | 用于生成结构化输出的语言模型。 |
| input_value | String | 发送给语言模型的输入消息。 |
| system_prompt | String | 指示语言模型如何格式化输出的指令。 |
| schema_name | String | 输出数据模式的名称。 |
| output_schema | Table | 模型输出的结构和数据类型。 |
| multiple | Boolean | [已弃用] 始终设置为 True。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| structured_output | 数据 | 结构化输出是基于定义模式的数据对象。 |
旧版组件
旧版组件可供使用,但不再受支持。
创建列表
此组件动态创建一个具有指定字段数量的记录。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| n_fields | Integer | 要添加到记录中的字段数量。 |
| text_key | String | 用作文本的键。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| list | List | 包含指定字段数量的动态创建列表。 |
输出解析器
此组件将语言模型的输出转换为指定格式。它支持 CSV 格式解析,使用 Langchain 的 CommaSeparatedListOutputParser 将 LLM 响应转换为逗号分隔的列表。
此组件仅提供格式化指令和解析功能。它不包含提示。您需要将其连接到单独的 Prompt 组件,以创建 LLM 使用的实际提示模板。
Output Parser 和 Structured Output 组件都可以格式化 LLM 响应,但它们的使用场景不同。Output Parser 更简单,专注于将响应转换为逗号分隔的列表。当您只需要一个项目列表时使用此组件,例如 ["item1", "item2", "item3"]。Structured Output 更复杂和灵活,允许您定义包含不同类型多个字段的自定义模式。当您需要提取具有特定字段和类型的结构化数据时使用此组件。
使用此组件
- 创建一个 Prompt 组件,并将 Output Parser 的
format_instructions输出连接到它。这确保 LLM 知道如何格式化其响应。 - 在 Prompt 组件中编写您的实际提示文本,包括
{format_instructions}变量。例如,在您的 Prompt 组件中,模板可能如下所示
_10{format_instructions}_10请列出三种水果。
-
将
output_parser输出连接到您的 LLM 模型。 -
输出解析器将其转换为 Python 列表:
["apple", "banana", "orange"]。
参数
输入
| 名称 | 类型 | 描述 |
|---|---|---|
| parser_type | String | 解析器类型。目前支持“CSV”。 |
输出
| 名称 | 类型 | 描述 |
|---|---|---|
| format_instructions | String | 传递给提示模板,以包含 LLM 响应的格式化指令。 |
| output_parser | Parser | 构建的输出解析器,可用于解析 LLM 响应。 |