在 Langflow 中集成 NVIDIA Retriever Extraction
NVIDIA Retriever Extraction 也称为 NV-Ingest 和 NeMo Retriever Extraction。
NVIDIA Retriever Extraction 组件集成了 NVIDIA nv-ingest 微服务,用于文本文件的数据摄取、处理和提取。
nv-ingest 服务支持 PDF、DOCX 和 PPTX 文件类型的多种提取方法,并包括预处理和后处理服务,如分割、分块和嵌入生成。
NVIDIA Retriever Extraction 组件导入 NVIDIA Ingestor 客户端,通过请求 NVIDIA 摄取端点来摄取文件,并将处理后的内容作为 Data 对象列表输出。Ingestor 接受用于从其他文本格式提取数据的附加配置选项。要配置这些选项,请参阅组件参数。
先决条件
-
一个 NVIDIA Ingest 端点。有关设置 NVIDIA Ingest 端点的更多信息,请参阅 NVIDIA Ingest 快速入门。
-
NVIDIA Retriever Extraction 组件需要为您的 Langflow 环境安装额外的依赖项。要在虚拟环境中安装依赖项,请运行以下命令。
- 如果您已经克隆并从源代码安装了 Langflow 仓库
_10source **YOUR_LANGFLOW_VENV**/bin/activate_10uv sync --extra nv-ingest_10uv run langflow run- 如果您正在从 Python Package Index 安装 Langflow
_10source **YOUR_LANGFLOW_VENV**/bin/activate_10uv pip install --prerelease=allow 'langflow[nv-ingest]'_10uv run langflow run
在流程中使用 NVIDIA Retriever Extraction 组件
NVIDIA Retriever Extraction 组件接受 Message 输入并输出 Data。该组件调用 NVIDIA Ingest 微服务的端点来摄取本地文件并提取文本。
要在您的流程中使用 NVIDIA Retriever Extraction 组件,请按照以下步骤操作
- 在组件库中,点击 NVIDIA Retriever Extraction 组件,然后将其拖到画布上。
- 在 Base URL 字段中,输入 NVIDIA Ingest 端点的 URL。或者,将端点 URL 添加为 Global variable
- 点击 Settings,然后点击 Global Variables。
- 点击 Add New。
- 命名您的变量。将您的端点粘贴到 Value 字段中。
- 在 Apply To Fields 字段中,选择您想要全局应用此变量的字段。在此示例中,选择 NVIDIA Base URL。
- 点击 Save Variable。
- 点击 Select files 按钮选择您想要摄取的文件。
- 选择要从文件中提取的文本类型。该组件支持文本、图表和表格。
- 选择是否将文本分割成块。在组件的 Configuration 选项卡中修改分割参数。
- 点击 Run 摄取文件。
- 要确认组件正在摄取文件,请打开 Logs 面板查看流程的输出。
- 要将处理后的数据存储在向量数据库中,请向您的流程添加 AstraDB Vector 组件,并将 NVIDIA Retriever Extraction 组件通过 Data 输出连接到 AstraDB Vector 组件。
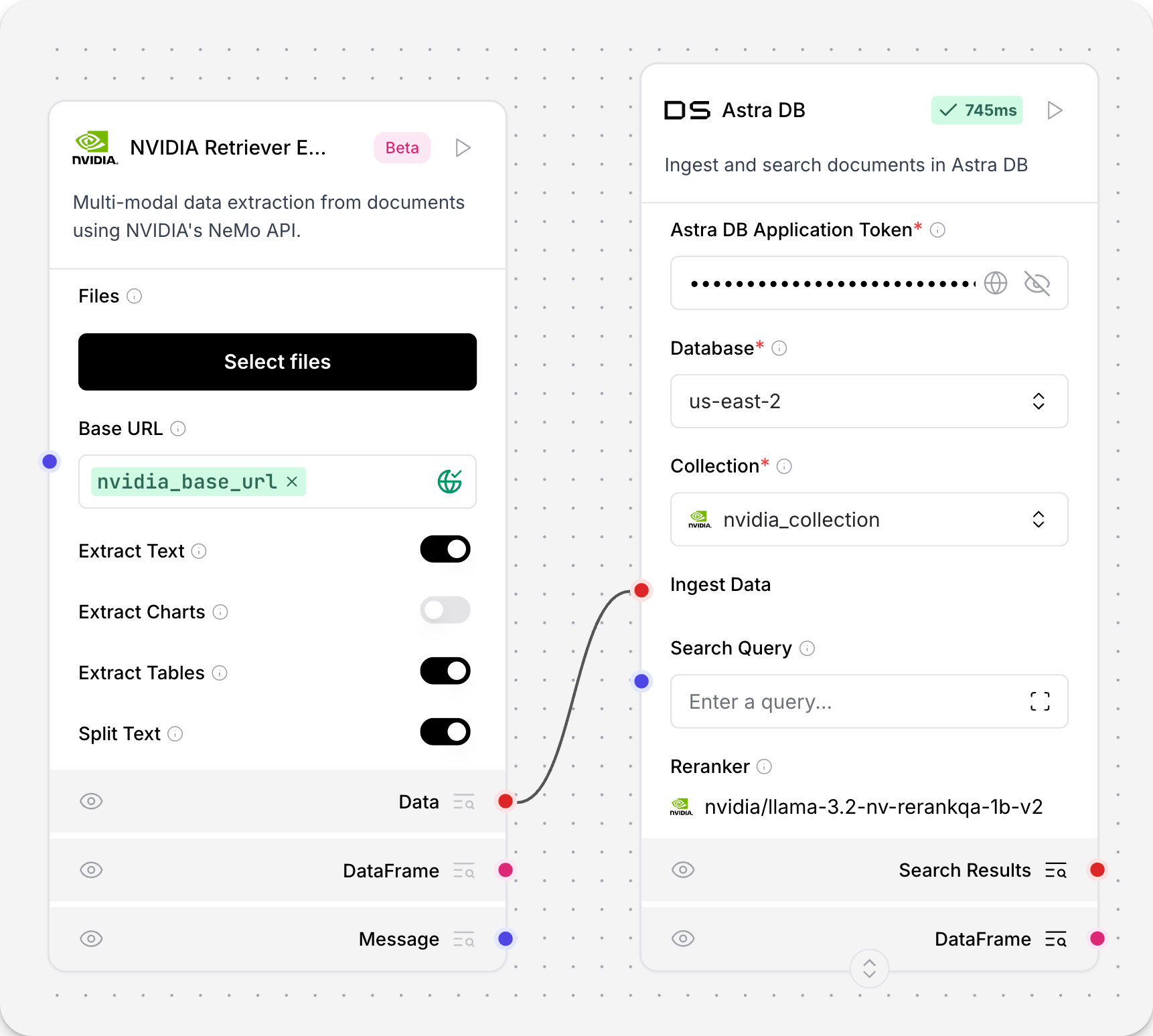
- 运行流程。检查您的 Astra DB 向量数据库以查看处理后的数据。
NVIDIA Retriever Extraction 组件参数
NVIDIA Retriever Extraction 组件具有以下参数。
有关更多信息,请参阅 NV-Ingest 文档。
输入
| 名称 | 显示名称 | 信息 |
|---|---|---|
| base_url | NVIDIA 摄取 URL | NVIDIA 摄取 API 的 URL。 |
| path | 路径 | 要处理的文件路径。 |
| extract_text | 提取文本 | 从文档中提取文本。默认值:True。 |
| extract_charts | 提取图表 | 从图表中提取文本。默认值:False。 |
| extract_tables | 提取表格 | 从表格中提取文本。默认值:True。 |
| text_depth | 文本深度 | 提取文本的层级。选项:'document'、'page'、'block'、'line'、'span'。默认值:document。 |
| split_text | 分割文本 | 将文本分割成更小的块。默认值:True。 |
| split_by | 分割方式 | 如何分割成块。选项:'page'、'sentence'、'word'、'size'。默认值:word。 |
| split_length | 分割长度 | 根据 'split_by' 方法确定的每个块的大小。默认值:200。 |
| split_overlap | 分割重叠 | 与前一个块重叠的段数。默认值:20。 |
| max_character_length | 最大字符长度 | 每个块中的最大字符数。默认值:1000。 |
| sentence_window_size | 句子窗口大小 | 当 split_by=sentence 时,从前一个和后一个块中包含的句子数量。默认值:0。 |
输出
NVIDIA Retriever Extraction 组件输出一个 Data 对象列表,其中每个对象包含
text:提取的内容。- 对于文本文档:提取的文本内容。
- 对于表格和图表:提取的表格/图表内容。
file_path:源文件名和路径。document_type:文档类型(“text”或“structured”)。description:内容的附加描述。
输出根据 document_type 的不同而异
-
document_type: "text"的文档包含- 从文档中提取的原始文本内容,例如 PDF 或 DOCX 文件中的段落。
- 直接存储在
text字段中的内容。 - 使用
extract_text参数提取的内容。
-
document_type: "structured"的文档包含- 从表格和图表中提取并经过处理以保留结构信息的文本。
- 使用
extract_tables和extract_charts参数提取的内容。 - 从
table_content元数据处理后存储在text字段中的内容。
目前不支持图像,处理时会跳过。